DeepSeek v4 1.6T: Day 0부터 Day 43까지의 시간 경과별 성능
Huawei · GB300 NVL72 · MI355X · B200 — Day 0 추론 성능, InferenceX, 26일 만의 100배 성능 향상, 백만 토큰당 비용, Huawei 950DT 추론 트레이스 분석
DeepSeek v4의 출시는 오픈 모델 커뮤니티에 또 하나의 진전을 의미한다. 놀랍지 않게도 이 역시 중국 연구소의 산물이다. 시간이 지남에 따라 이 모델의 성능이 어떻게 변화하는지는 AI 생태계에 매우 중요하다. 오픈소스 InferenceX 엔지니어링 팀은 여러 날 밤을 새워 이 모델의 Day 0, Day 1, Day 2 및 그 이후의 성능을 측정해 그 결과를 세상에 공개했다. 이 글에서는 DeepSeek v4의 Day 0 성능을 조명하고, 모델 출시 이후 몇 주에 걸쳐 이루어진 의미 있는 개선들을 설명한다. 또한 DeepSeek v4 모델 아키텍처의 핵심 구성 요소를 설명하고, 그것이 부분적으로 Huawei Ascend 추론을 위해 어떻게 공동 설계(co-design)되었는지 논의한다.
블로그 포스트의 2장에서는 Huawei Ascend 950DT에서의 DeepSeek v4 Day 0 추론을 종합적으로 분석한다. 이 글은 Ascend 950DT의 DeepSeek v4 추론에 대한 최초의 분석으로서, Huawei가 성능 최적화를 위해 수행한 연산<>통신 구간(lap) 및 다양한 연산 스트림을 분해해서 살펴본다.
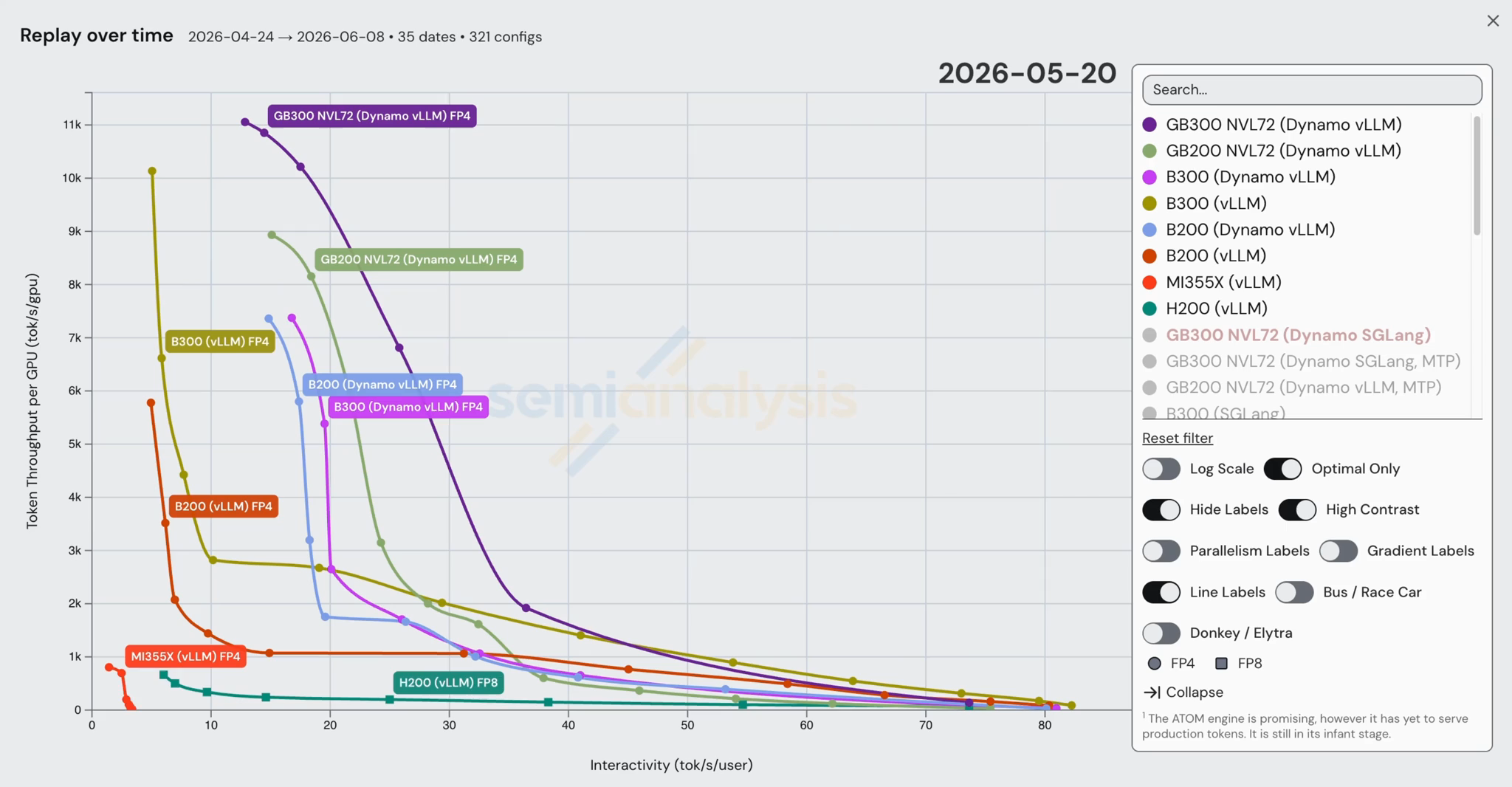
InferenceX의 핵심 목표 중 하나는, 특히 모델의 Day 0 출시 기간 동안 각 SKU의 성능을 오픈소스 이미지와 레시피를 사용해 가능한 한 많은 프레임워크에서 기록하는 것이다. 이 이미지와 레시피의 성능이 얼마나 좋은지와 무관하게 기록한다. 이를 통해 시간 경과에 따른 개선을 추적할 수 있으며, 우리는 이것이 각 칩의 실제 배포 가능한 성능을 가장 잘 반영한다고 믿는다. 아래 영상은 Day 0부터의 vLLM/SGLang 비-MTP 구성에 대한 반복적 개선을 각각 보여준다. day 0부터의 MTP 구성도 보려면 inference.com을 방문하라.
)
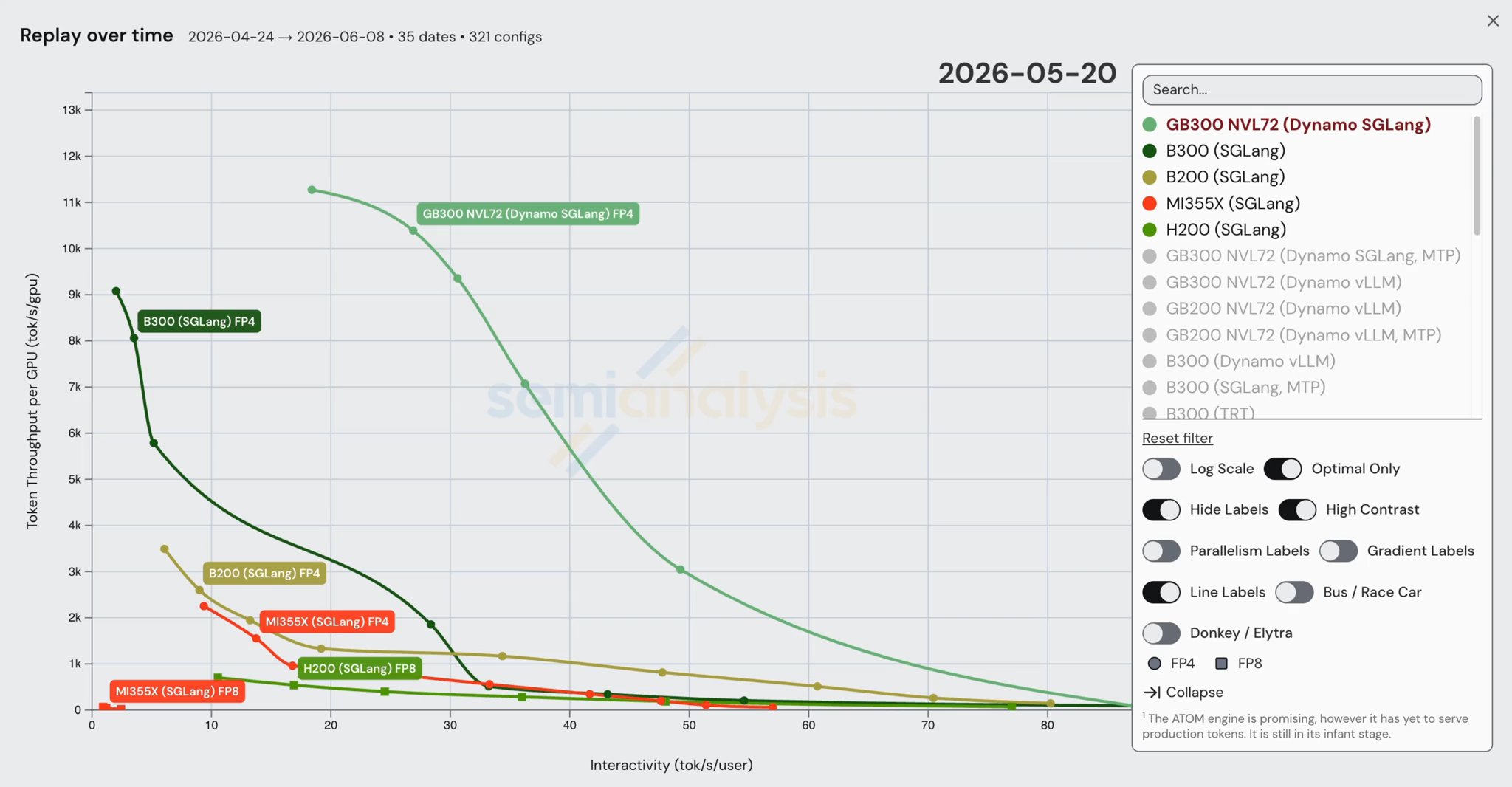)
이 그래픽들은 DeepSeek v4 추론 성능 튜닝에 투입된 수천 시간의 엔지니어링을 반영하며, 대부분의 최적화는 SGLang/vLLM의 master 브랜치에 병합되었다. InferenceX의 북극성(north star) 목표 중 하나는 성능의 단순한 스냅샷이 아니라 시간 경과에 따른 반복적 개선을 조명하는 것이다. 결국 엔지니어링에서는 과정에서 배우는 것이 최종 결과만큼이나 중요한 경우가 많기 때문이다.
DeepSeek v4 Pro 초기에 CUDA vLLM, CUDA SGLang, 그리고 CUDA vLLM의 분리형 프리필(disaggregated prefill)은 별다른 설정 없이도 훌륭하게 작동했으며, 이는 vLLM과 SGLang 오픈 생태계의 강점을 입증했다. 이 추론 엔진들은 글로벌 ML 생태계에 너무나 근본적이어서, 양 팀 모두 각각 Inferact와 RadixArk라는 회사를 설립했고, 각각 수억 달러를 조달해 오픈소스 추론 엔진의 성장을 이어가고 있다.
Huawei Ascend 역시 자사 문서에서 DeepSeek v4에 대한 Day 0 추론 성능 지원을 기술하고 시연했다. 현재 중국은 오픈 모델 분야를 지배하고 있으며, Kimi K2.6는 코딩에서 여전히 Jensen의 Nemotron Committee Coalition의 Nemotron 3 Ultra를 앞서고 있다. 게다가 NVIDIA의 자체 TensorRT-LLM은 DeepSeek v4에서 잘 작동하지 않았고, 우리 SemiAnalysis가 그들의 오픈소스 mHC 커널 실행(launch) 코드를 수정해야 했다. 우리의 패치를 리베이스하고 병합해 준 NVIDIA 엔지니어들에게 감사한다!
ROCm 역시 DeepSeek v4 출시 후 처음 며칠간 잘 작동하지 않았다. 다만 HaiShaw의 기술 리더십 아래 AMD SGLang 엔지니어링 팀은 첫 달 동안 성능을 대폭 향상시켜 Day 26까지 100배 이상의 성능을 달성했다. AMD 소프트웨어의 진전에 관한 좋은 점과 나쁜 점은 곧 공개될 종합 기사 「State of AMD 2026」에서 더 자세히 다룰 예정이다.
모든 성능 추적은 우리의 오픈소스 GitHub 저장소에 문서화되어 있다. 저장소가 유용하다고 느낀다면 별(star)을 눌러 달라: https://github.com/SemiAnalysisAI/InferenceX
우리의 전체 DeepSeek v4 성능 대시보드도 확인할 수 있다.
SemiAnalysis InferenceX 추론 이니셔티브는 OpenAI, Oracle, Microsoft, Weka, PyTorch Foundation, vLLM, SGLang, CoreWeave 등 ML 커뮤니티의 많은 이들의 지원을 받고 있다.

InferenceX 팀은 vLLM 커뮤니티 메인테이너들과 Inferact, 그리고 RadixArk, Meta 등 전 세계 SGLang 메인테이너들이 지속적으로 수행하는 엔지니어링 노력에 깊이 감사한다. 또한 이 프로젝트에 Day 0 지원을 제공한 NVIDIA 엔지니어 Kedar Potdar, Ankur Singh, Xin Li, Alec Flowers 및 많은 NVIDIA 엔지니어들에게 감사를 전한다. ROCm 스택에서 DeepSeek v4 Pro에 대한 Day X 지원을 제공한 AMD 엔지니어링 팀에도 감사를 표한다.
안타깝게도 DeepSeek v4가 출시되었을 때 우리의 GB300 클러스터가 다운된 상태였다. 다행히 CoreWeave가 오픈소스 커뮤니티와 메인테이너들에게 연산 자원을 제공해 주었고, 여분의 개발용 GB300 NVL72 랙 두 대를 급히 마련해 주었다. 우리의 GB300 결과는 오직 그들의 지원 덕분에 얻을 수 있었으며, 우리는 결과를 더욱 개선하기 위해 이 자원을 24시간 내내 활용하고 있다.

저수준 벤치마킹, InferenceX, 또는 기타 흥미로운 기술 작업에 참여하고 싶다면, 본인의 엔지니어링 역량을 보여주는 세 가지 요점과 함께 letsgo@semianalysis.com 으로 이력서를 보내라. 가능하다면 프로젝트, 작업, 지식을 보여줄 수 있는 GitHub 저장소 링크, 웹사이트, 블로그를 첨부하라.
섹션 1: DeepSeek v4 Pro Day 0 성능
이 섹션에서는 먼저 DeepSeek v4 Pro의 Day 0 기본(out of the box) 성능을 논의한다. 처리량-상호작용성(throughput-interactivity) 곡선, 서로 다른 병렬화 방식이 처리량 대 상호작용성에 어떻게 유리하게 작용하는지, 그리고 InferenceX V2 기사에서 설명한 MTP 및 분리형(disaggregated) 추론과 같은 기타 추론 최적화를 참조한다.
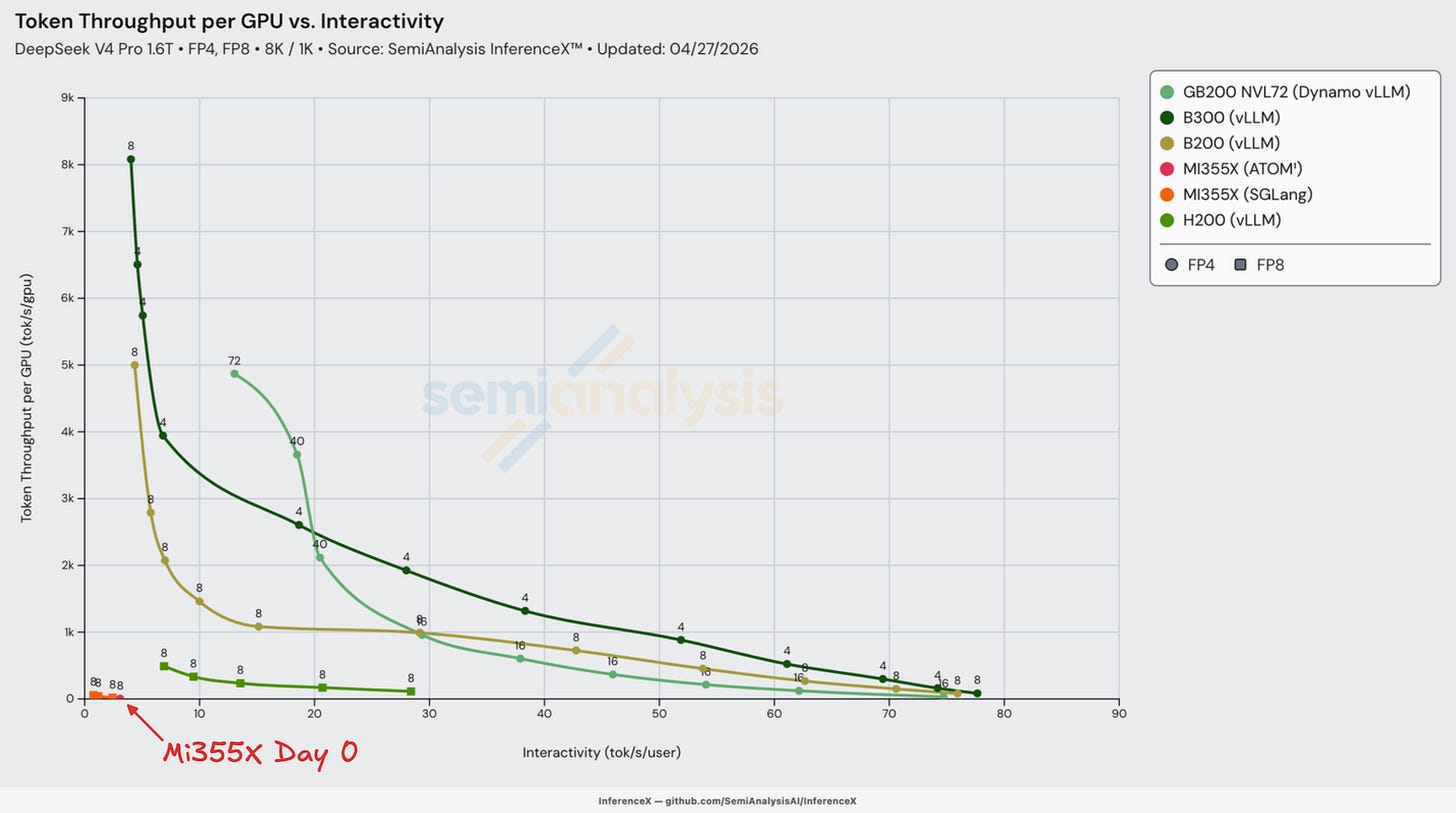
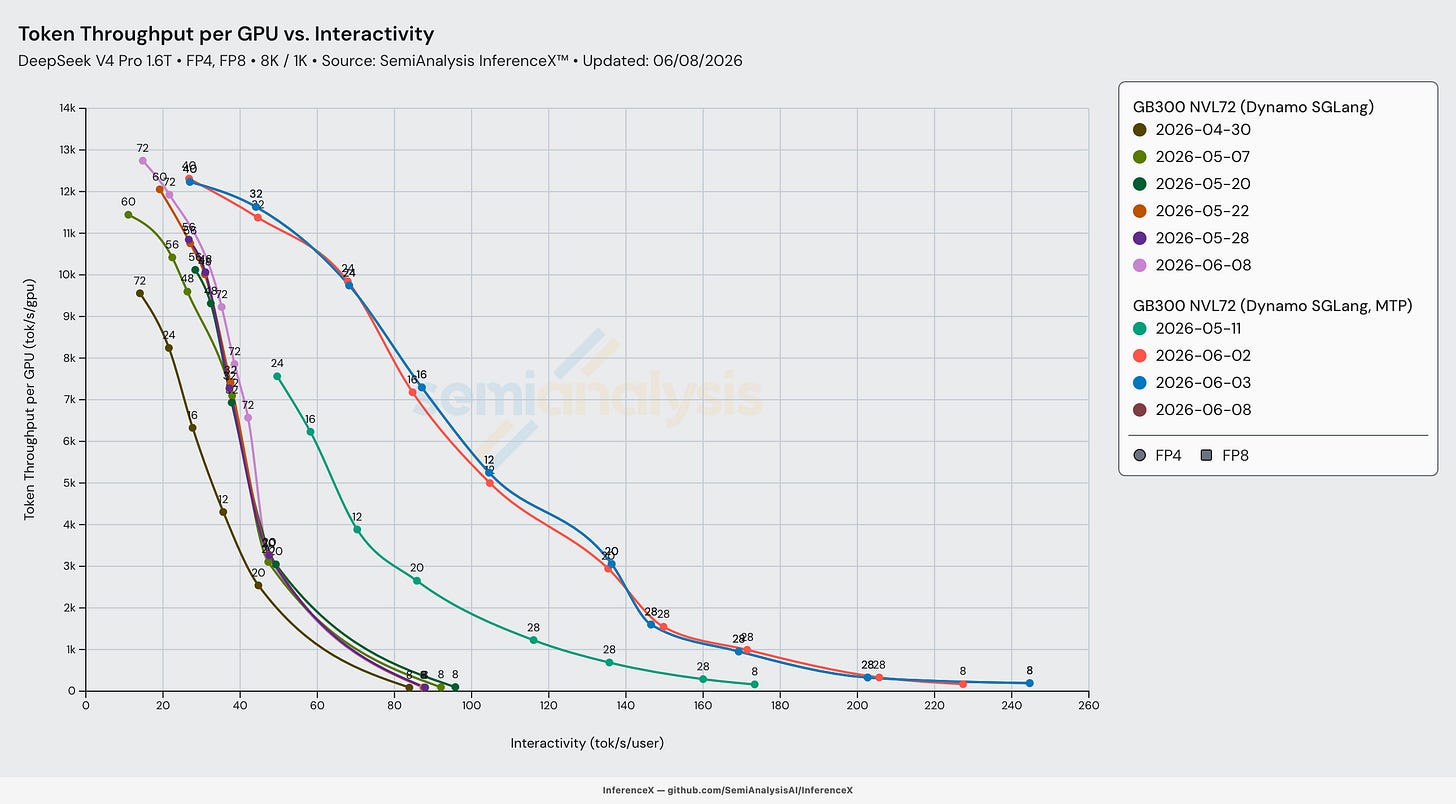
다음 두 그래프는 우리가 기록할 수 있었던 모든 Day 0 레시피를 보여준다. 대부분의 레시피는 혼합 FP4 MoE - FP8 Attention 양자화 가중치를 활용하는 네이티브 모델 체크포인트를 사용한다(H200과 MI355X SKU는 예외). DeepSeek v4 Pro의 네이티브 FP4+FP8 체크포인트가 MI355X에서 Day 0에 사용 불가능했기 때문에, 우리에게는 풀 FP8 비-네이티브 체크포인트를 사용하는 선택지밖에 없었다.
안타깝게도 AMD SGLang 및 AMD vLLM 분산(distributed) 추론은 여전히 DeepSeek v4 Pro에서 작동하지 않는다.

SGLang과 vLLM으로 돌아가면, 두 엔진 모두 모델이 공개된 순간부터 CUDA 플랫폼에서 네이티브 DeepSeek v4 Pro를 지원했다. 특히 B200/B300과 같은 최신 SKU에 대해 광고된 대부분의 레시피는 큰 문제 없이 기본 설정에서 작동했다.
아래 그래프는 SGLang Day 0 성능을 보여준다:
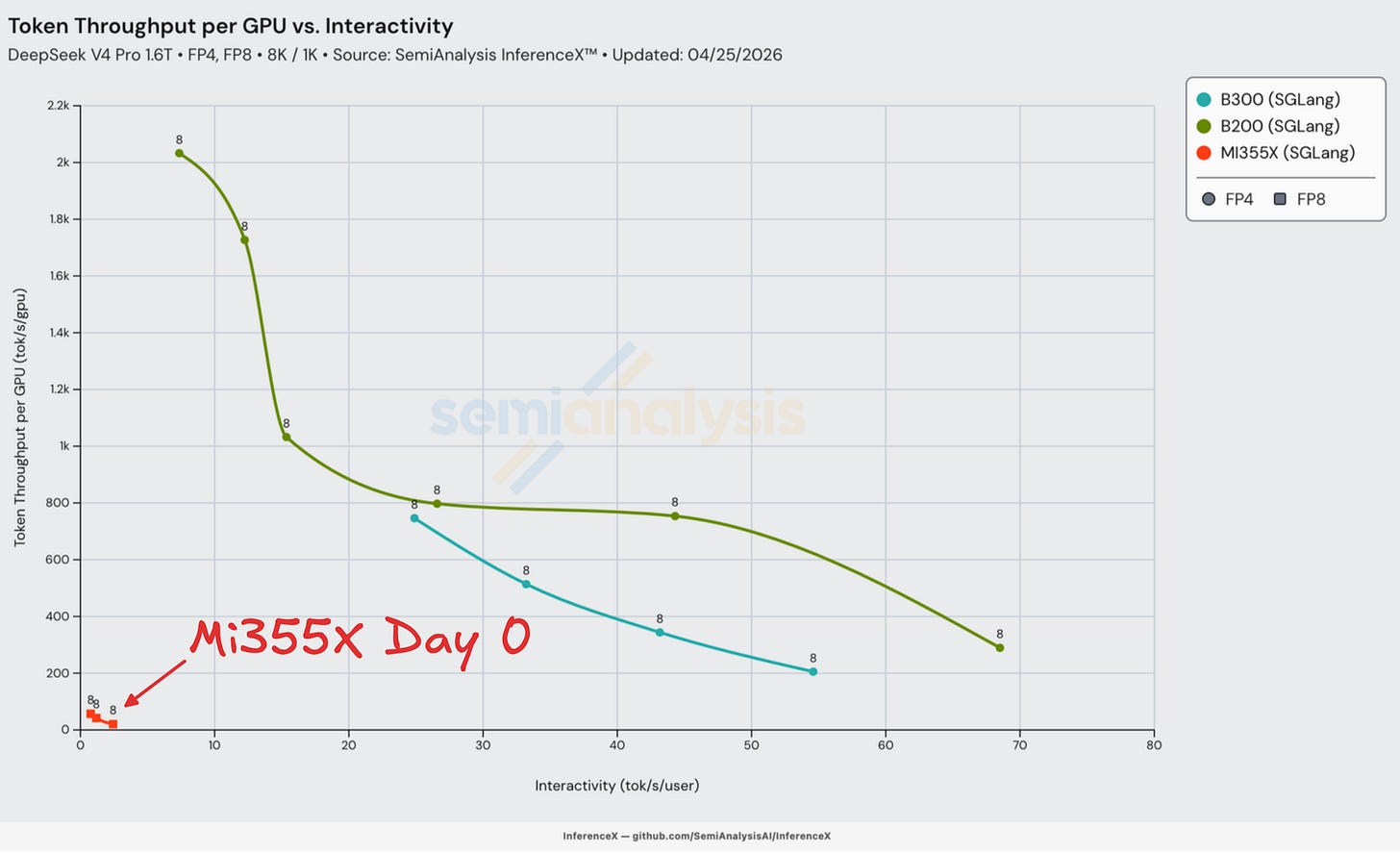
이제 각 Day 0 결과 그룹을 더 깊이 살펴보자.
GB200 NVL72에서의 Day 0 멀티노드 분리형 프리필
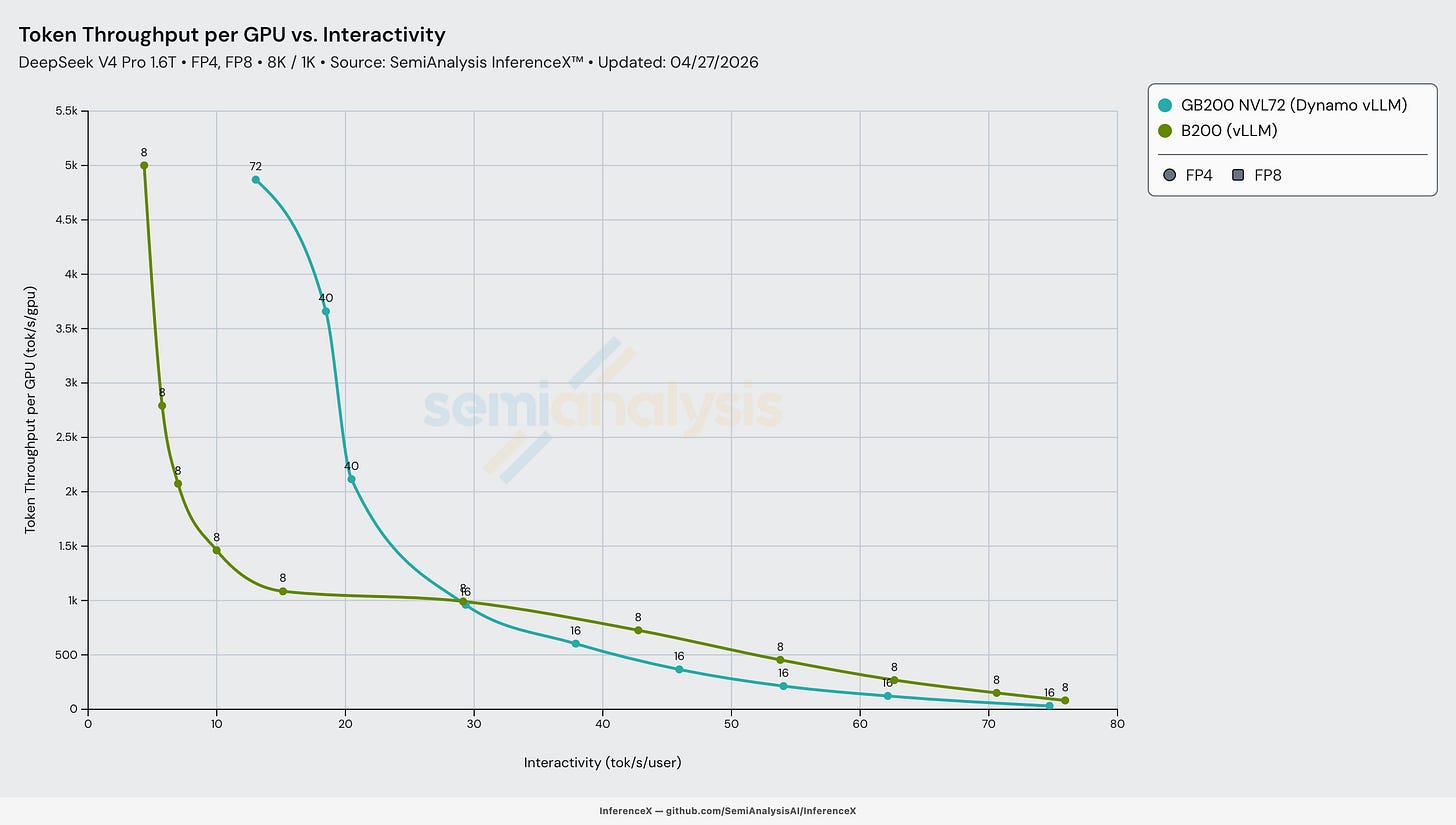
vLLM과 NVIDIA는 srt-slurm 상에서 GB200 분산 추론 Dynamo vLLM 레시피를 매우 빠르게 제공했다. 분리형 추론과 광역 전문가 병렬화(WideEP, Wide Expert Parallelism)는 달러당 성능을 상당히 개선할 수 있는 추론 최적화 기법이다. 독자들은 InferenceX V2 기사에서 이 기법들에 대해 더 알아볼 수 있다. 레시피 자체는 기초적이었다: 프리필에서 eager 모드, KV 캐시 전송에 NIXL 사용. 우리는 이 레시피를 독립적으로 재현했으며, 더 낮은 상호작용성 구성을 사용해 B200 실행 대비 최대 5배 더 나은 결과를 달성했다.
이는 "CUDA 해자(moat)"가 작동하는 좋은 예다. CUDA에서는 최신 오픈 모델에 대해 분산 추론이 Day 0에 가깝게 지원되는 경향이 있다.
Day 3 다중 토큰 예측(MTP) 추측 디코딩
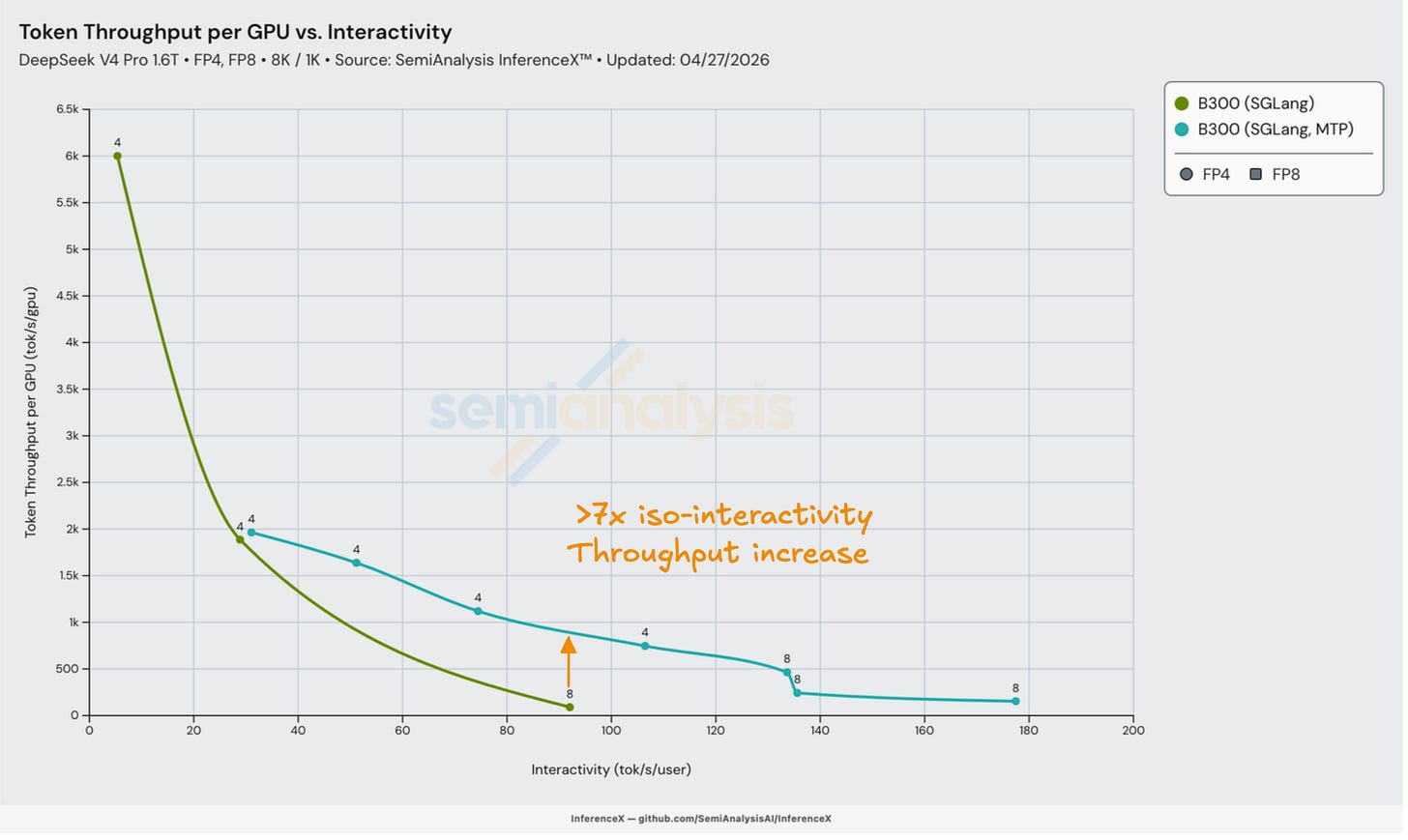
DeepSeek v4에 대한 첫 MTP 지원은 Day 3에 SGLang에서 제공되었다. MTP를 사용하면 더 높은 상호작용성에서 처리량이 상당히 개선되었다. MTP와 그것이 메모리 병목(memory-bound) 소형 배치 크기 디코드에 어떻게 이점을 주는지에 대한 설명은 InferenceX V2 기사에서 찾을 수 있다.
Day 0 ROCm AMD MI355X의 실망
AMD MI355X의 ROCm으로 넘어가면, DeepSeek v4에 대한 우리의 Day 0 결과는 혼란스러웠다. 오픈소스 생태계의 대부분 AMD 사용자들도 혼란에 빠져 있었다. MI355X는 Day 0에 FP8만 실행할 수 있었고, 아래 전체 Day 0 차트에서 좌측 하단에 위치한 결과를 냈다. 추론은 기술적으로는 작동했지만, 사용자당 초당 1~2 토큰이라는 극도로 낮은 상호작용성 수준 — 평균적인 사용자 읽기 속도에 크게 못 미치는 — 때문에 사용 불가능한 경험이었다.
우리는 AMD의 HaiShaw 외 인사들이 제공한 SGLang PR의 Day 0 WIP 레시피를 사용했다. 이것이 Day 0에 찾을 수 있던 유일하게 작동하는 레시피였다. 안타깝게도 그 성능은 실망스러웠고 네이티브 FP4+FP8 체크포인팅은 작동하지 않았다 — 이는 아마도 덜 성숙한 ROCm 생태계 때문일 것이다. 다만 기사 뒷부분에서 다루겠지만, HaiShaw의 팀은 결국 해냈다. 고전적인 제1원리 기반 엔지니어링을 통해 Day 0부터 Day 26까지 성능을 100배 이상 향상시키는 놀라운 작업을 해냈다.
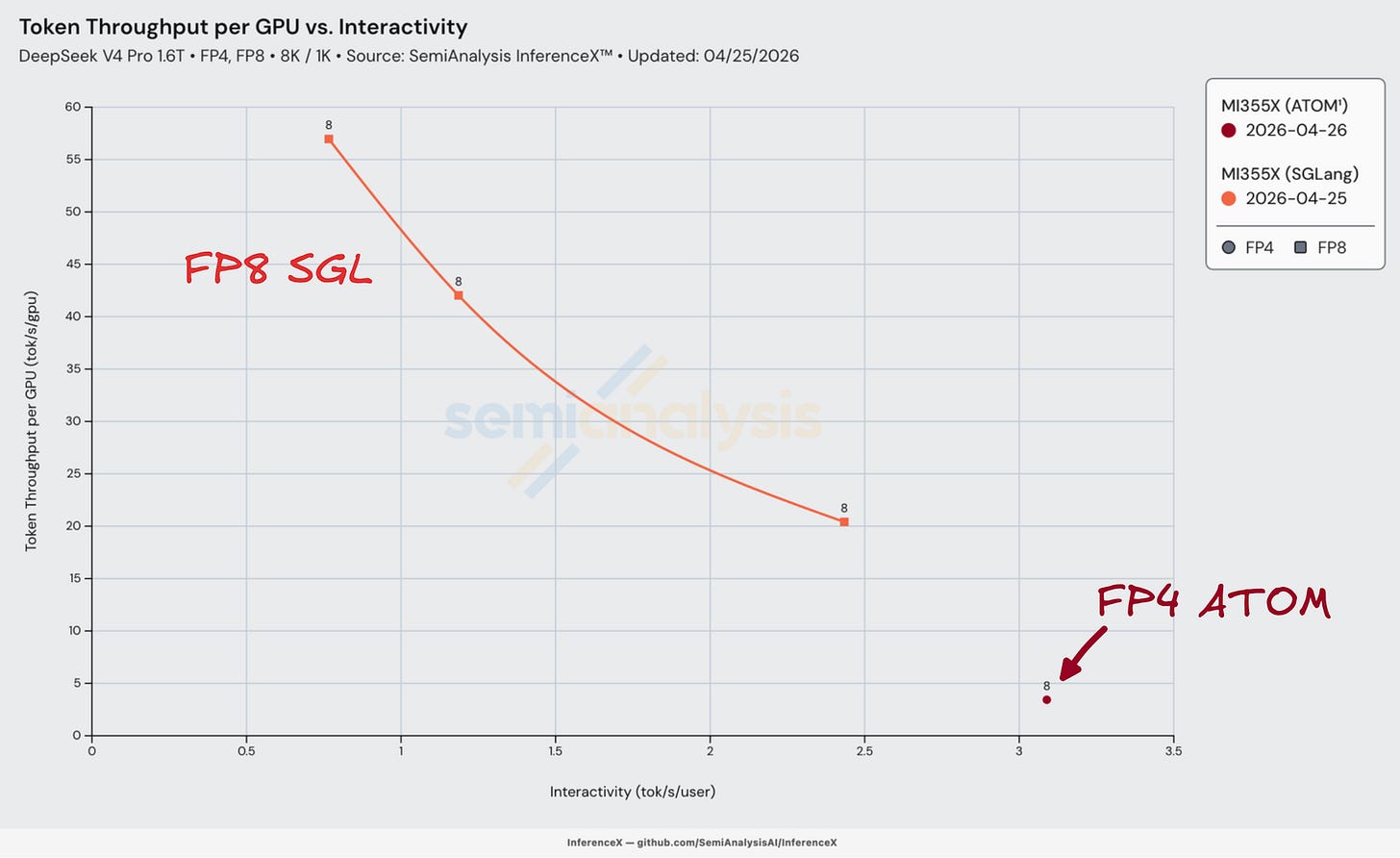
AMD ATOM 추론 엔진의 실망
ATOM은 상호작용성 면에서는 다소 더 나았지만, 동시성(concurrency)이 1보다 큰 경우에는 여전히 부족했다. DeepSeek v4 초기에 우리는 kv_cache[:1,...]가 하드코딩된 ATOM #650을 사용했는데, 이는 KV 캐시가 단일 시퀀스 슬롯에 고정됨을 의미했다. 가용 슬롯이 하나뿐이라 두 번째 동시 요청은 KV 상태를 저장할 곳이 없었다. 배칭을 가능하게 하는 인프라가 아직 갖춰지지 않았기 때문에, 우리는 배치 크기 1(사용자 1명)만 실행할 수 있었다.
ATOM은 또한 거의 모든 핫 패스(hot path)를 폴백(fallback)으로 실행했다. AITER의 fused_moe가 GFX950에서 깨져 있어 FP4 MoE는 Triton으로 강제되었고, AITER 커널이 충돌해 mHC 사전 투영(pre-projection)은 Torch로 패치되어 eager 실행을 강제했다.
NVIDIA TensorRT-LLM 버그 및 Day 0 DeepSeek v4 Pro 미지원
TensorRT는 mhcFusedHcKernel.cu에 단일 하드코딩 상수 FHC_HIDDEN = 4096이 있었기 때문에 DeepSeek v4를 기본 설정에서 지원하지 못했다. SHAPE_K, residual/x TMA 디스크립터, MMA 커널 템플릿 인스턴스화가 모두 그 hidden size에 묶여 있었던 것이 문제였다. 모든 이전 DeepSeek 모델과 DeepSeek v4 flash는 hidden size가 4096이어서 당분간은 이것이 통했다. 하지만 DeepSeek v4 Pro 추론을 실행하려 하면 "mhcFusedHcLaunch: hidden_size=7168 not supported (only 4096)" 가드 오류가 발생했다.
NVIDIA 엔지니어들도 이 가드 오류에 부딪혔는데, DeepSeek v4 Pro의 7168 hidden size를 지원하는 코드를 추가하는 대신 그냥 가드를 제거해 버렸다. 놀랍지도 않게, 그러자 오류가 사라졌다.
이 "수정" 때문에, 환경 변수 TRTLLM_MHC_ENABLE_FUSED_HC=0을 사용하지 않는 한 커널이 오로지 4096용으로만 컴파일되고 7,168 호출을 거부하는 것이 전혀 없는 상태가 일주일 넘게 지속되었다. 기본 설정(fused HC 기본 활성화; B300 = SM10x → MMA 경로)에서 DeepSeek v4 Pro의 기본 trtllm-serve는 7,168 텐서를 4,096으로 배선된 커널에 넣게 된다. 이 설정으로 추론을 실행하면 즉각적인 충돌 없이 추론이 진행되지만 숨겨진 결과가 있다: 엔진이 hidden state를 손상시키고 무효한 생성 결과를 만들어 낸다. 이는 우리가 작성한 PR에서 수정되었으며, 이렇게 단순한 문제가 인지되기까지 일주일이 걸리고 PR이 승인되기까지 며칠이 더 걸렸다는 점이 놀라웠다.
문제를 진단하고 fused HC hidden size 불일치로 범위를 좁히는 데 걸린 시간 동안, 우리는 이미 DeepSeek v4 Pro 출시 후 Day 9에 도달해 있었다. 이 사건은 네이티브 오픈 SGLang과 네이티브 vLLM 엔진 생태계의 강점을 입증하는 좋은 사례 연구다. 이 견고한 생태계 덕분에 Day 0 지원은 TensorRT-LLM이나 AMD의 ATOM 엔진보다 항상 네이티브 SGLang과 네이티브 vLLM에 먼저 도달한다(참고로 ATOM은 현재 프로덕션 고객이 0이다).
아래 그래프에서 오늘날 기준으로 TRT-LLM의 성능이 더 큰 배치 크기에서는 우수하지만 더 높은 상호작용성 수준에서는 뒤처지는 경향이 있음을 볼 수 있다.
(주: 원문에서는 이 위치에서 TRT-LLM 성능 비교 그래프를 언급하지만, 별도의 전용 도표 대신 Section 1의 종합 Day 0 플롯을 참조한다.)
섹션 1.5: 시간 경과에 따른 성능
기사 앞부분에서 언급했듯, 우리는 추론 엔진과 레시피 전반에 걸쳐 Day 0 성능의 스냅샷을 포착한다. 이는 시간 경과에 따른 성능 개선을 측정하는 기준선 역할을 하기 때문이다. 이 기준 성능을 바탕으로 다음과 같이 시간 경과에 따른 성능 개선을 분석하는 데이터를 측정하고 제시할 수 있다.
MI355X에서의 DeepSeek v4 Pro — 한 달 미만에 100배 개선
Day 0에 DeepSeek v4 Pro는 MI355X에서 기술적으로는 작동했지만, 어떤 프로덕션 워크플로에도 배포할 수 없는 수준임이 분명했다. 그러나 그 이후의 개선은 경이로웠다 — HaiShaw가 이끄는 AMD 팀이 DeepSeek v4 출시 후 한 달 미만에 처리량을 100배 이상 개선했다.
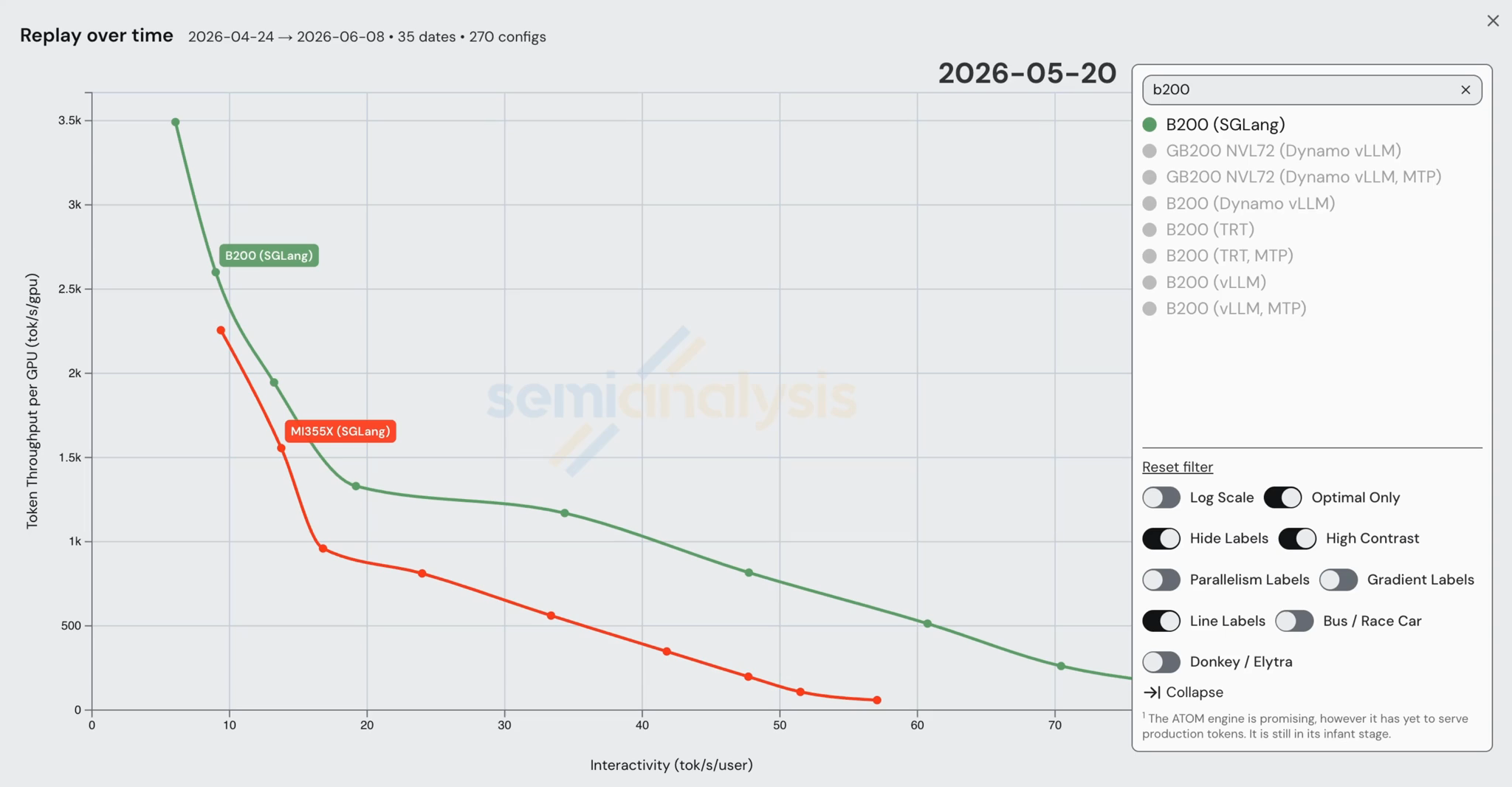)
위 차트는 4월 25일에 출시된 Day 0의 FP8 빌드 결과와 5월 27일에 출시된 FP4 빌드 결과를 비교했을 때, 처리량의 파레토 최적 경계(pareto-optimal frontier)가 어떻게 상승했는지 보여준다. 이 이득은 거의 전적으로 AMD가 PyTorch 네이티브 폴백 경로를 실제 AITER, Triton, TileLang, FlyDSL 커널로 교체한 데서 비롯되었다.
이득의 대부분을 견인한 두 단계가 있다. 가장 큰 백분율 개선은 사실 Day 0 기준 제출 이후 첫 번째 커밋에서 나왔다 — 팀은 손쉽게 딸 수 있는 성과(low hanging fruit)를 대거 정리하고 FP8 기준선에서 첫 반복을 크게 향상시켰다. 다음으로 큰 개선은 며칠 후 AMD 팀이 마침내 FP4 가중치 MoE를 작동시키면서 나왔다. 이로써 MoE 전문가를 FP8에서 네이티브 FP4(MXFP4)로 전환할 수 있게 되어 전문가-가중치 대역폭이 개선되었다. 이는 또한 FlashMLA와 희소 어텐션 인덱서(sparse-attention indexer)를 torch 폴백에서 TileLang 커널로 옮겼고 HIP 그래프를 활성화했다.
그다음 큰 개선은 모든 레이어에서 사용되는 AITER mHC 커널의 도입에서 비롯되었다. 이 개선으로 성능이 향상되어, 더 낮은 상호작용성 수준에서 MI355X가 DeepSeek v4 Pro에 대해 처음으로 H200 성능을 능가하는 것을 볼 수 있었다.
윈도우드 어텐션(windowed-attention) 커널이 실행되기 전에, 각 쿼리의 윈도우가 어떤 KV 캐시 슬롯을 포함하는지 알아야 한다. 이는 SWA-prepare가 수행하며, 이를 Triton으로 구현한 것도 개선에 도움이 되었다.
다음 큰 도약은 5월 19일, 팀이 남은 폴백을 제거하면서 나왔다: FlashMLA가 TileLang에서 Triton으로 옮겨졌고, AITER FlyDSL FP4 MoE 커널이 도입되었다. 팀은 또한 fused hash-topk, DSv4 radix attention, fused store-cache, fused WQA/WKV 투영, fused paged-compress를 활성화해 성능을 더욱 끌어올렸다. 동시성 스윕(concurrency sweep)도 1024로 늘려, 이전에는 존재하지 않던 고처리량·저상호작용성 경계 영역을 그려냈다.
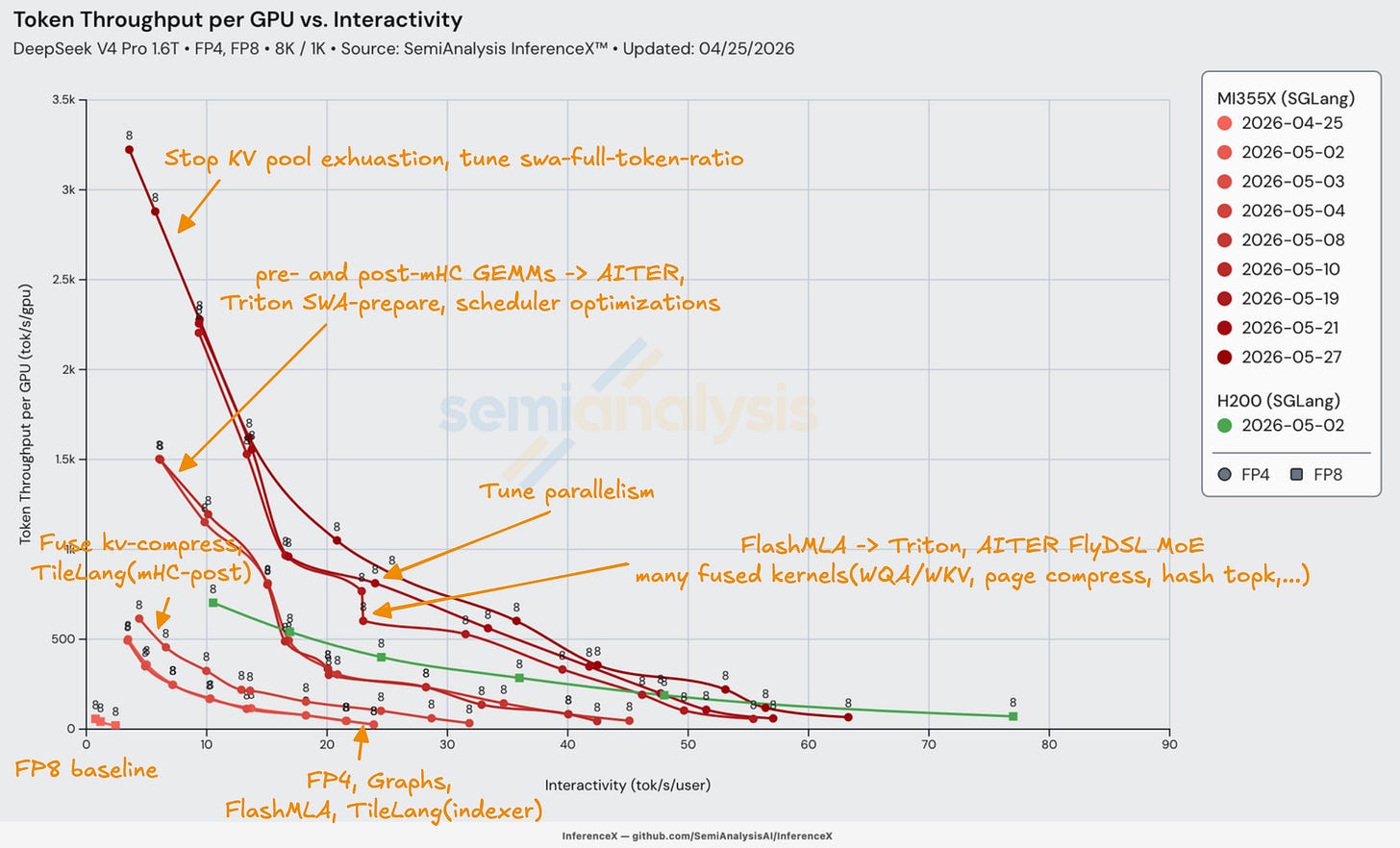
ATOM 역시 극적으로 개선되어, conc=1의 단일 점에서 전체 파레토 경계를 따라 괜찮은 처리량을 제공하는 수준으로 확장되었으며, 일부 지점에서는 H200을 능가했다. 첫 이득은 mHC 충돌 뒤에 있던 디바이스 할당 버그를 수정한 AITER 픽스 #2916에서 비롯되어 ATOM이 그 AITER 커널을 복원할 수 있게 했다. 다음으로 FP4 전문가가 AITER의 fused MoE 커널로 이동했고(Triton 오버라이드 제거), 희소 어텐션 OOM이 해소되어 eager 모드와 단일 시퀀스 한계를 제거할 수 있었다. 배칭 지원도 구현되어 스윕이 conc=1에서 conc 1–512로 확장되며 훨씬 더 나은 성능을 냈다.
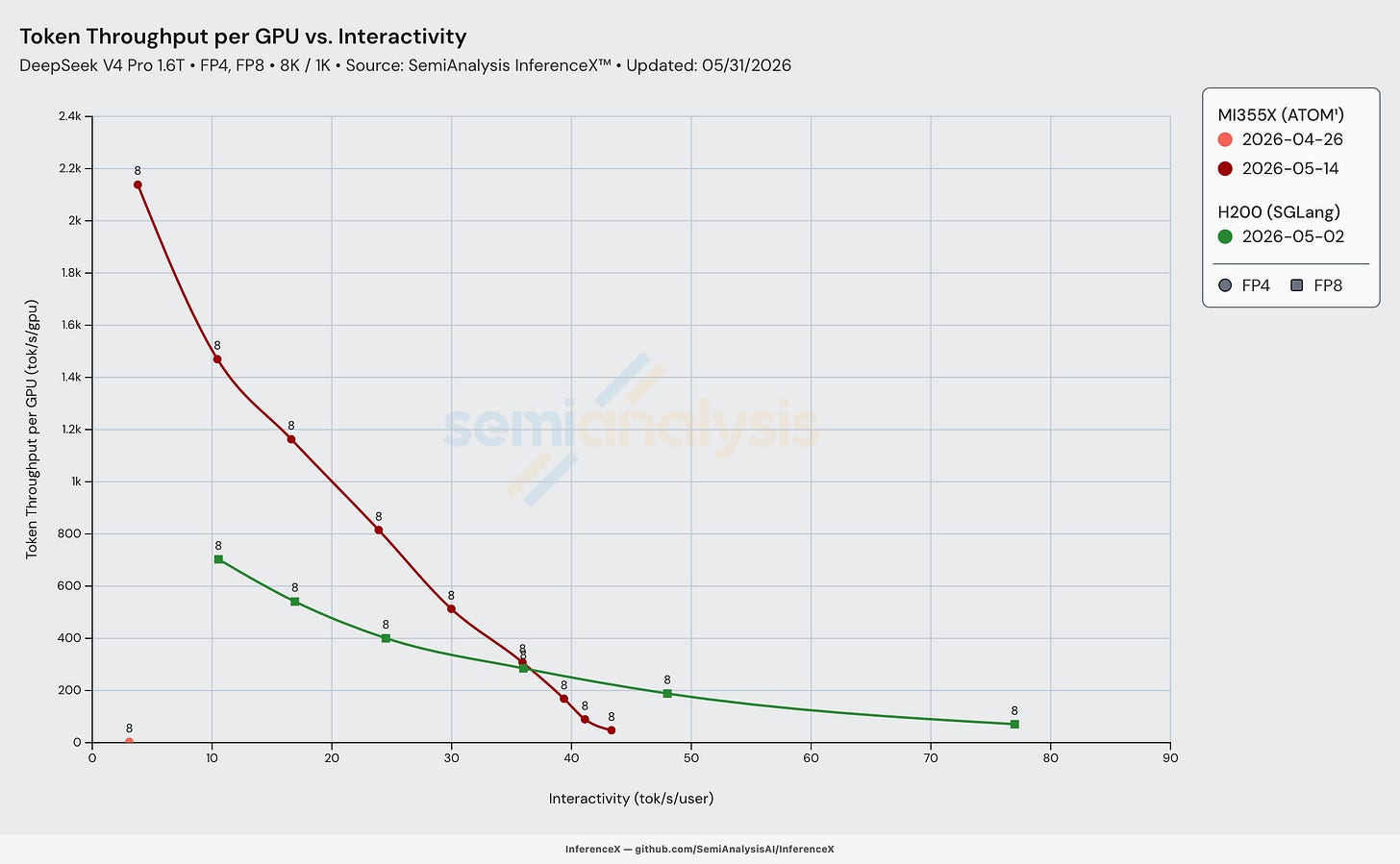
MI355X MTP
4주 차에는 MTP가 AMD의 모든 프레임워크에서 작동하여, 여러 배수의 상호작용성-처리량 개선을 제공했다. 다만 우리가 발견한 한 가지 일관된 특성은 MTP가 더 높은 처리량에서는 더 나쁜 결과를 내는 경향이 있다는 것이다. 이는 MTP가 메모리 병목 디코드의 연산 여유(compute slack)를 활용하기 때문으로, 연산 병목인 대형 배치 크기 디코드 작업에서는 MTP 비용이 초안 토큰(draft token)이 제공하는 이점을 초과한다.
B300
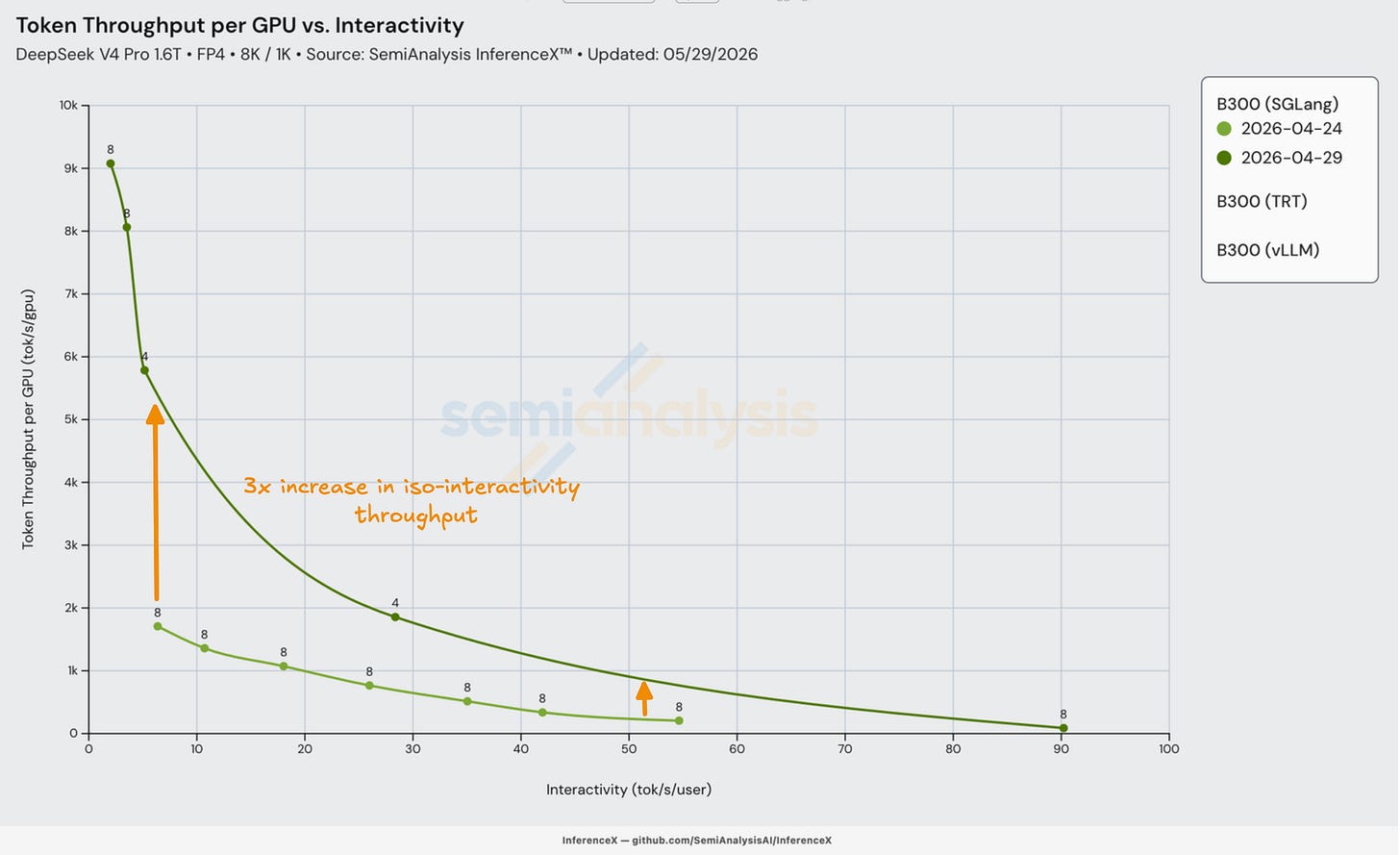
SGLang의 B300에서 DeepGEMM MegaMoE를 사용한 결과, 일주일도 안 되어 3배 개선을 보였다. 이는 전문가를 상주(resident) 상태로 유지하고 전문가별 커널 대신 하나의 메가 디스패치(mega-dispatch)를 수행하는 그룹화된 FP4 MoE GEMM의 사용, 그리고 EP8 대신 EP4를 사용하도록 튜닝한 데서 비롯되었다.
B200
B200의 성능은 B300과 비교적 유사했으며, 더 낮은 상호작용성에서는 B200에서 TRT가 우수했다. 그러나 TRTLLM은 기본 설정에서 작동하지 않는 반면, CUDA vLLM과 SGLang vLLM은 기본 설정에서 작동한다.
GB300 NVL72
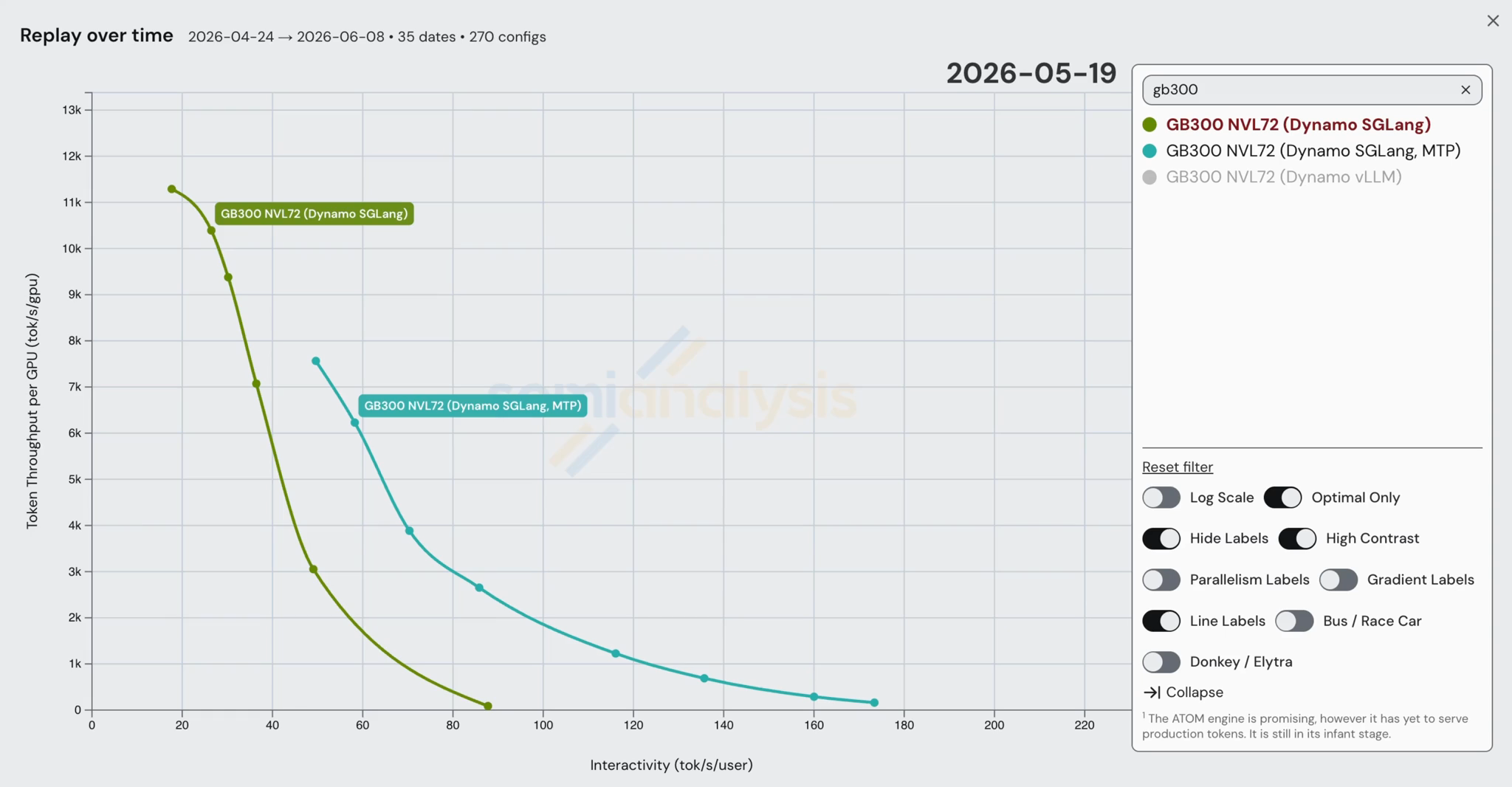)
GB300 SGLang MTP의 가장 극적인 개선은 6월 2일 W4A4(MXFP4) MegaMoE 구현에서 나왔다. 5월 7일에 사용되던 비-MTP 구현과 비교했을 때, 6월 2일 버전의 주요 개선은 커널이나 정밀도를 건드리지 않고 전적으로 GB300 디코드 토폴로지를 재작성한 데서 비롯되었다. Day 0 레시피는 대부분의 지점에서 한두 개의 프리필 워커가 공급하는 좁은 EP=8로 실행되고 동시성을 16,384로 제한했던 반면, 5월 20일 실행은 디코드를 EP=16으로 넓히고, 디코드 워커당 프리필을 4~12개 워커로 확장했으며, 동시성을 21,504까지 끌어올렸다.
위 그래프와 분석을 바탕으로, 더 큰 월드 사이즈(world size) 추론 시스템에서 예상되듯이 Wide EP가 GB300의 뛰어난 성능을 이끄는 주된 지렛대임을 알 수 있다. 이는 더 많은 GPU에 걸쳐 가중치 로딩을 분산 상각함으로써 제공된다. Wide EP에 대해 더 알아보려면 InferenceX V2 기사를 참고하라.
이러한 GB300 결과는 오직 CoreWeave의 지원 덕분에 가능했다.
B200 메가와트(MW)당 토큰 개선
vLLM 엔진을 사용한 B200의 경우, 전체 공급 유틸리티 메가와트당 토큰 처리량이 50 tok/s/user 상호작용성에서 Day 0에 MW당 초당 300,000 토큰에 도달했고, 6월 5일까지 MW당 초당 거의 500,000 토큰으로 개선되었다.
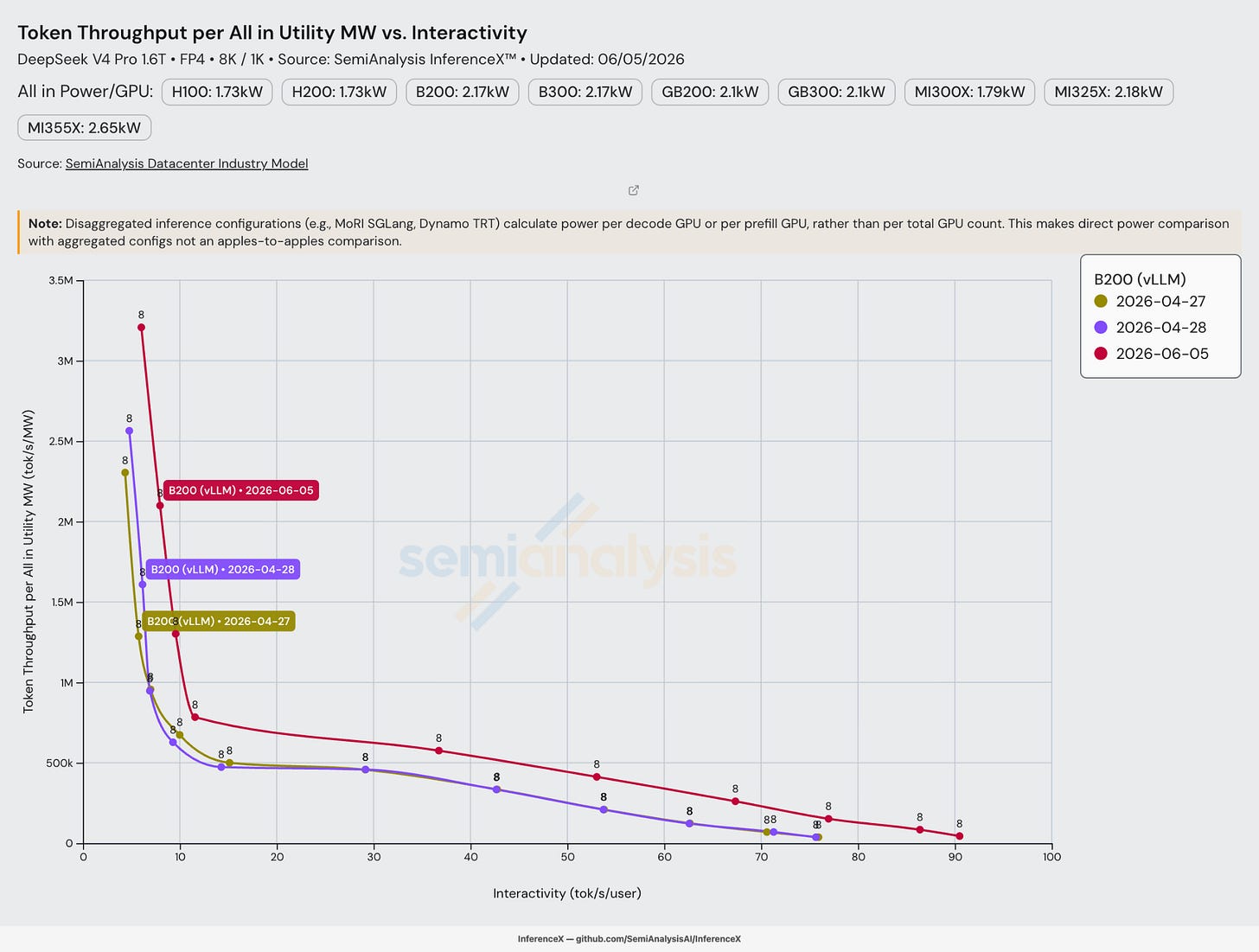
전체 공급 유틸리티 MW당 토큰은 함대(fleet) 규모에서 투자 수익률을 고려하기에 가장 좋은 성능 지표다. 이는 PUE와 데이터센터 오버헤드를 반영하기 때문에 GPU당 원시 토큰 처리량보다 더 많은 정보를 더한다. B200의 전체 유틸리티 전력 한계가 GPU당 약 2.17 kW로 고정되어 있으므로, 약 300k에서 약 500k tok/s/MW로의 약 1.7배 도약은 순수한 소프트웨어 이득을 반영한다.
처리량 경계를 밀어올린 것과 동일한 종류의 최적화(MegaMoE 그룹화 FP4 GEMM, 더 넓은 EP, FP4 가중치 경로, 스케줄러 튜닝)는 MW 단위의 전체 유틸리티 전력이 변하지 않기 때문에 곧바로 전력 효율로 이어진다.
많은 조직은 추론 함대를 희소 자원인 유틸리티 전력을 최대한 활용하는 관점에서 접근한다. 핵심 질문은 주어진 활용률과 가격에서 공급된 MW를 어떻게 가능한 한 많은 청구 토큰으로 전환하느냐다. 이 분석은 MW당 매출, 전체 유틸리티 전력당 토큰, MW당 capex 같은 지표로 가장 잘 설명되며, 우리의 Tokenomics 모델이 다루도록 설계된 비즈니스 사례다.
2026년 6월 6일 기준 현재 성능
성능 개선에 관한 이 섹션을 마무리하며, 시스템 및 추론 엔진 전반의 최고 성능을 빠르게 살펴보자. SGLang을 사용할 때 GB300은 계속해서 다른 모든 추론 시스템을 압도하며, GB300 NVL72의 랙 규모 월드 사이즈의 이점을 입증한다.
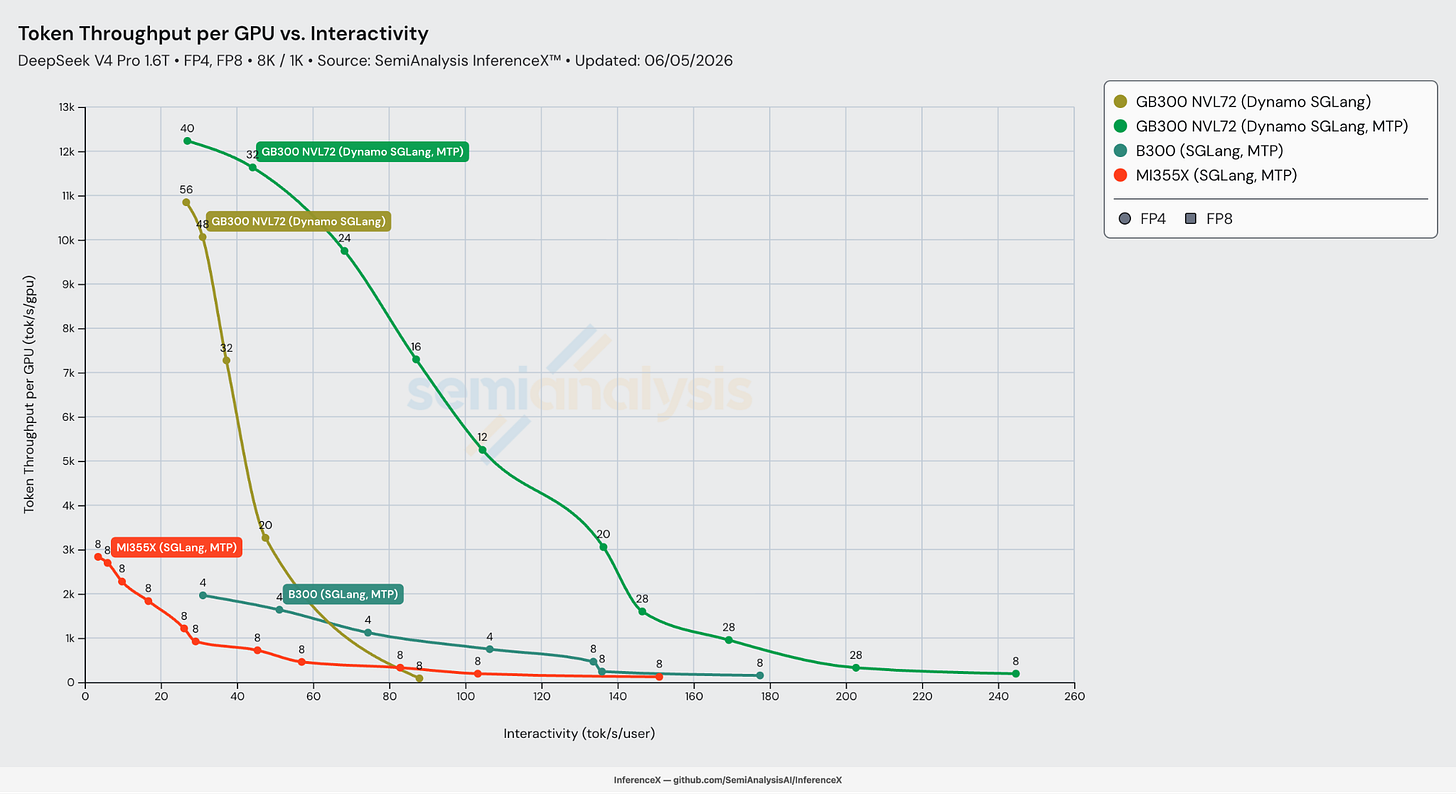
MTP를 켜면, GB300으로 서빙하는 것은 우리가 분석한 모든 상호작용성 수준에서 타의 추종을 불허한다. GB300의 백만 출력 토큰당 비용은 입력 8k 토큰, 출력 1k 토큰을 가정할 때 50 tok/s/user에서 $0.156에 이른다. 총소유비용(TCO)을 어떻게 계산하는지는 우리의 TCO 모델에서 더 알아볼 수 있다.
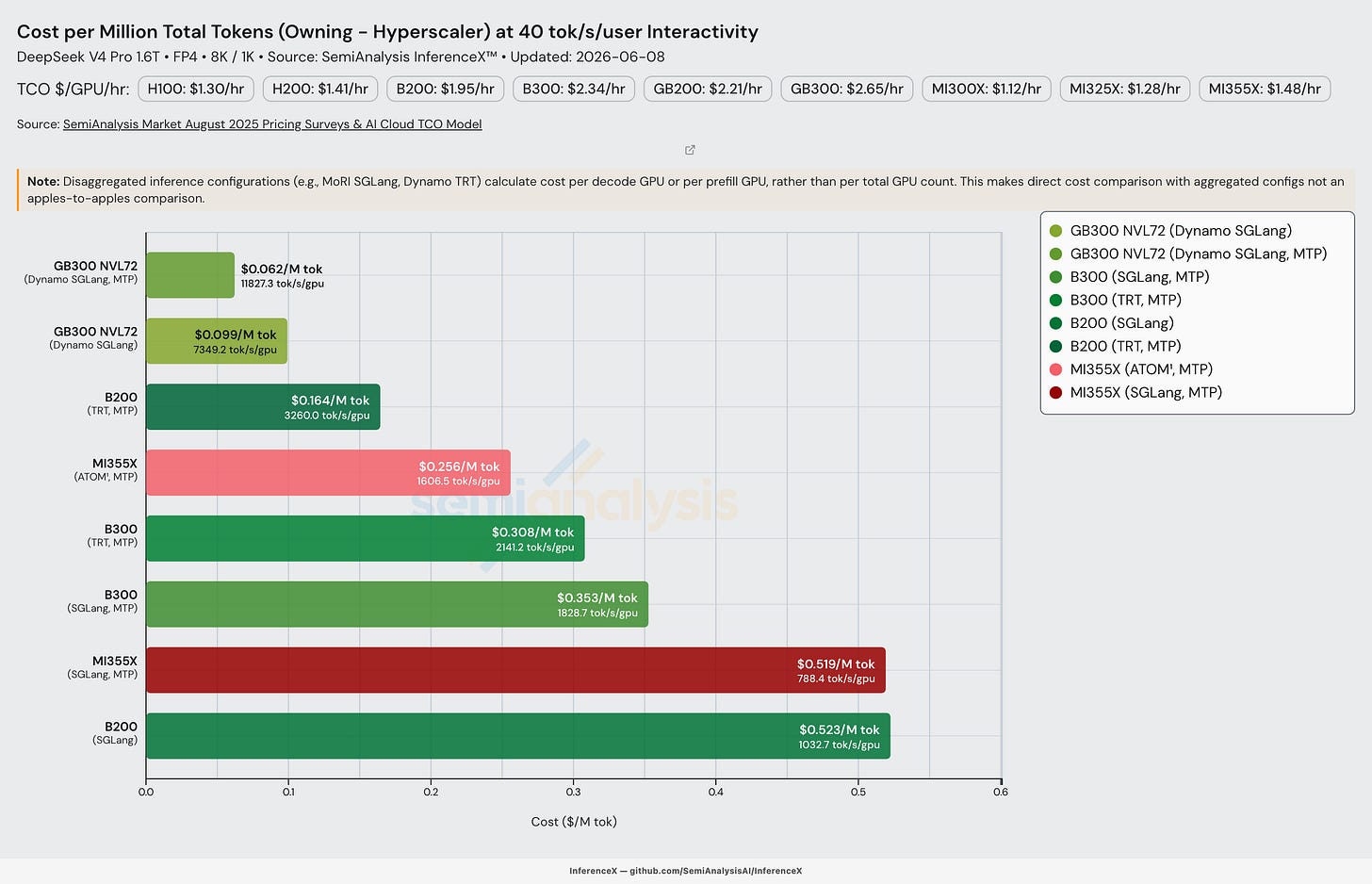
랙 규모의 이점은 근본적으로 스케일업(scale-up) 도메인 이야기다. NVL72는 72개의 GPU를 단일 NVLink 도메인에 넣어, 서빙 스택이 전문가 병렬화를 충분히 넓게 실행해 DeepSeek v4의 MoE 디스패치/컴바인 all-to-all을 더 느린 스케일아웃 패브릭으로 흘려보내지 않고 전적으로 NVLink 상에서 유지할 수 있게 한다. 동시에 전문가-가중치 로드를 훨씬 더 많은 랭크에 걸쳐 상각한다.
8-GPU NVLink 섬(island)을 InfiniBand로 스케일아웃하는 B200과 B300은 그 벽에 훨씬 더 일찍 부딪히며, MI355X는 스케일업 도메인 크기와 집합 통신 스택(collective-stack) 성숙도 양면에서 더 뒤처져 있다. 이러한 랙당 처리량 우위를 배포된 서빙 용량으로 전환하는 것은 별개의 문제로, 각 SKU가 실제로 얼마나 온라인 상태인지 — 분기별 SKU별 출하량과 ASP, 고객별 설치 기반 및 유효 FLOPS — 에 달려 있으며, 이는 우리의 Accelerator & HBM 모델에서 추적한다.
ROCm vLLM DeepSeek v4 Pro의 실망
ROCm에 관해서는, 네이티브 vLLM의 진전이 네이티브 SGLang에 비해 훨씬 더 느렸다. ROCm vLLM의 성능은 CUDA vLLM 대비 크게 뒤처져 있다. 문제의 일부는 AMD가 (주요 고객 다수가 사용하는 추론 엔진인) 네이티브 vLLM에 집중하는 대신 (프로덕션 토큰을 0개 서빙하는 추론 엔진인) ATOM에 다시 집중하고 있다는 점이다. 이에 대해서는 곧 공개될 「State of AMD 2026」 기사에서 더 다룰 예정이다(AMD 추론의 좋은 점, 나쁜 점, 추한 점을 다룬다). 우리가 다룰 긍정적인 발전 중 하나는, 비-DeepSeek v4 모델에 대해 오픈소스 기본 설정의 업스트림 AMD vLLM에서 분산 추론의 기능적 활성화가 마침내 이루어졌다는 점이다. 거기에 도달하기까지 수개월이 걸렸고, AMD vLLM 팀이 다뤄야 할 영역은 여전히 많이 남아 있다.
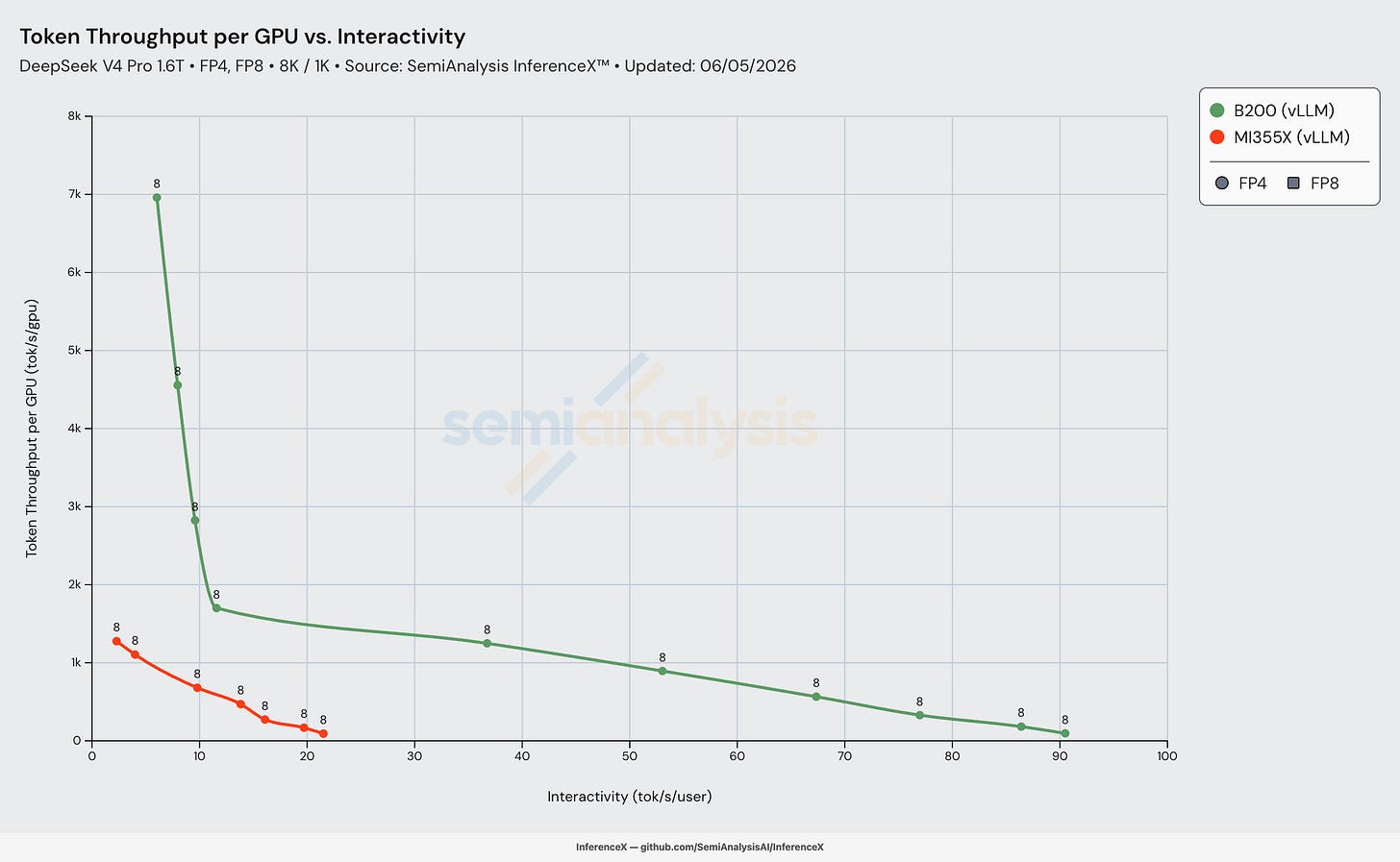
DeepSeek v4의 다음 단계
vLLM
vLLM의 계획은 DeepSeek V4 로드맵 이슈(#40902)에서 추적되며, 구현 PR #40860에 코드가 반영되었고 SemiAnalysis의 InferenceX 대시보드 대비 벤치마킹에 대한 설명이 담겨 있다. FP4 인덱서와 초기 MegaMoE 지원은 이미 구현되었고, 이제 Hopper도 지원된다. DeepSeek v4를 위한 vLLM의 남은 작업은 다섯 영역에 걸쳐 있다:
- 핵심 모델 지원: 지속적인 MegaMoE 작업(PR #40833)과 NVFP4 지원.
- 런타임 및 병렬화: Model Runner V2 통합, MTP 최적화, 프리필/디코드(PD) 최적화, 파이프라인 병렬화 지원.
- 커널 통합: 페이지드 프리필 커널, 빠른 top-k 커널, 더 많은 수평 융합(horizontal fusion), DeepEP V2, DeepSeek 자체 TileKernels와의 통합.
- KV 캐시: KV 캐시 오프로딩 — PD + CPU 오프로딩(PR #39654) 및 분산 KV 오프로딩 포함.
- 하드웨어 지원: 완료된 Hopper 지원 외에, SM120 및 AMD 지원이 주요 잔여 과제로 남아 있다.
여기서의 핵심 테마는 주변 시스템에 있다: 새로운 모델 러너, 파이프라인 병렬화, KV 오프로딩, 더 넓은 하드웨어 커버리지. SemiAnalysis의 오픈소스 공개 EcosystemX 대시보드에 대한 향후 업데이트는 NVIDIA, AMD, TPU, Trainium, Huawei 등 모든 주요 AI 칩에 걸쳐 모든 주요 ML 오픈 라이브러리의 소프트웨어 진화, CI 커버리지, 대기열 시간을 시각화할 것이다.
SGLang
SGLang의 계획은 NVIDIA가 DeepSeek v4의 네트워크 다이어그램을 중심으로 구성한 성능 최적화 트래커(#23666)에 담겨 있으며, 블록 단위로 하나씩 살펴본다. 일부 항목은 초기 지원 PR(#23600)에서 이미 부분적으로 다뤄졌을 수 있으며, 커뮤니티 기여를 환영한다.
여기에는 세 가지 상위 목표가 반영되어 있다: 디코드를 위한 CUDA 그래프 지원, 프리필을 위한 부분(piecewise) CUDA 그래프 지원, 런타임 가중치 처리 없애기. 또한 가중치 준비는 매 스텝마다가 아니라 한 번만 이루어져야 한다. 이 세 가지 상위 목표 안에서, 체크리스트는 V4의 구성 요소별로 그룹화된다:
- mHC: fc_hc_fn GEMM(N 차원이 작아 특수 커널이 필요할 수 있음)에 대해 TF32/BF16 시도, 1/RMS + 곱셈 융합, 단일 커널 hc_split_sinkhorn 및 hc_post, 어텐션 및 MoE 블록에서 MulSum + RMSNorm(+ FP8/MXFP8 양자화) 융합.
- HCA(Compressor 포함): fc_qa + fc_kv를 하나의 FP8 GEMM으로 수평 융합, q-norm/k-norm 및 RMSNorm+RoPE 융합, topk_idx를 제거하는 비-희소 MQA 경로, 복사/연결 없이 압축 및 SWA KV 캐시에서 직접 읽는 MQA, 단일 커널 InvRoPE, 융합된 Compressor 상태 갱신(kv-update + ape-Add + score-update), 그리고 HCA(특히 Compressor)를 디코드용 CUDA 그래프 호환으로 만들기.
- CSA(Indexer + Compressor): 희소 경로에 대한 유사한 직접 캐시 읽기, fc_compressor + fc_idx_compressor 및 fc_qb + fc_idx_qb의 선택적(P1) 융합, (RoPE +) Hadamard + MXFP4 양자화 융합, 효율적인 MXFP4 BMM+ReLU 커널(MulSum, 나아가 Top-1024와 융합 가능), Indexer 및 Compressor의 CUDA 그래프 호환성.
- MoE: 라우터 GEMM에 대한 TF32/BF16 검토, 라우팅 경로(softplus + sqrt + bias-add + Top-6 + gather + norm + multiply)를 최소한의 커널로 축약, 블록 단위 FP8 및 MXFP8 활성화 양자화 융합, 공유 전문가와 라우팅 전문가 FC13이 모두 단일 커널이 되도록 보장, 라우팅 전문가 앞의 작은 정렬 커널 감사.
SGLang의 초점은 작은 연산들의 연쇄를 단일 융합 커널로 교체하고, 새로운 어텐션 변형이 캐시를 제자리에서 읽도록 하며, 디코드 경로를 완전히 CUDA 그래프로 끌어들이는 데 있다.
섹션 2: Huawei 950DT Day 0 DeepSeek v4 분석
DeepSeek v4는 Huawei Ascend에서 1급(first class) Day 0 지원을 받은 첫 주요 오픈 모델이었으며, 실제로 DeepSeek 공식 API의 일부는 Day 0부터 Huawei에서 서빙되었다. 우리는 DeepSeek v4에 대한 Huawei 성능 수치를 보유하고 있으며, 동일한 벤치마크 하니스(harness)를 사용해 Huawei 대 H200 및 B200의 추론을 동일 조건(apples to apples)으로 비교하는 심층 후속 기사를 공개할 계획이다.
곧 공개될 우리의 공개 오픈소스 SemiAnalysis EcosystemX 대시보드는 Ascend 스택을 포함한 모든 주요 AI 칩에 대해 모든 주요 ML 오픈 라이브러리의 소프트웨어 진화와 CI 커버리지를 시각화할 것이다.
CANN
CANN(Compute Architecture for Neural Networks)은 Huawei가 자사 Ascend 칩에서 AI 워크로드를 실행하기 위한 소프트웨어 툴킷이다. 2025년 8월부터 그들은 더 많은 개발자를 유치하고 NVIDIA의 지배력을 "깎아내리기(chip away)" 위해 CANN을 오픈소스화했다. 특히 미국 정부가 CUDA 칩의 중국 반입을 강하게 제한하고 있는 중국 내에서 그러하다.

Day 0에 CANN은 Ascend 칩에 대한 최적화 가이드와 벤치마크 수치를 공개했다. 이를 통해 우리는 Huawei의 CANN 전략을 엿볼 수 있다: 중국 국내 모델 출시를 겨냥한 풀스택 추론 최적화를 통해 Ascend를 경쟁력 있게 만드는 것. Huawei는 DeepSeek이 새 아키텍처를 출시하면 CANN이 커널, 그래프 경로, 양자화, 서빙 통합, 배포 레시피를 제공할 수 있음을 중국 생태계에 보여주려 하고 있다.
벤치마킹 중 우리가 관찰한 CANN 팀의 흥미로운 방법론 하나는 MTP 초안 토큰의 AR(수용률, acceptance rate) 또는 AL(수용 길이, acceptance length)을 다루는 방식이었다. MTP 벤치마킹은 간단하지 않은데, 벤치마크의 AR/AL이 사용자의 실제 사용 사례와 다를 수 있기 때문이다. 예를 들어 벤치마크는 평균적으로 셋 중 두 개의 초안 토큰을 수용할 수 있지만, 배포된 사용 사례가 매우 다양하면 결국 평균적으로 셋 중 1.5개만 수용하게 될 수도 있다.
이는 사용자가 벤치마크 대비 더 낮은 성능을 보게 되어 자신의 설정이 잘못되었다고 잘못 결론지을 수 있음을 의미한다. 우리는 InferenceX v2 기사에서 AR을 MTBench와 비교함으로써 이 문제를 다뤘다. 향후 벤치마크 버전에서는 실제 트레이스(real traces)를 사용해 이 격차를 종합적으로 해결할 것이다.
이 특이점을 해결하기 위해 Huawei는 대신 전체 디코드 스텝이 마지막 MTP 모듈과 일치하도록 시간을 측정하여, 토큰당 시간이 아니라 디코드 스텝당 시간을 기록한다. 그러면 최종적으로 공개된 벤치마크 결과는 사용자가 자신의 사용 사례 MTP AL을 곱해 비교 가능한 성능 지표를 도출하도록 요구하는데, 이는 성능을 비교하는 매우 우아한 방식이다.
NVIDIA 골리앗이여, 마을에 새로운 다윗이 나타났다 — Ascend 950
Huawei의 Ascend 950 칩 내부 코드명은 "David(다윗)"이며, 이 코드명은 CANN 코드베이스에서 여러 차례 참조된다. 의심할 여지 없이 그들이 NVIDIA라는 골리앗에 맞서는 다윗이라고 믿기 때문이다.

SIMT/SIMD 950 칩은 두 가지 변형으로 나온다: 950PR과 950DT. PR은 Prefill and Recommendation(프리필 및 추천)을 의미하며, 더 나은 비용-성능을 갖춘 저비용 칩이다. DT는 Decode and Training(디코드 및 학습)을 의미하며, 이 변형은 더 높은 메모리 대역폭과 더 높은 성능을 갖춘다. 둘 다 듀얼 다이 UMA 아키텍처를 사용하는 동일한 Ascend 950 다이를 기반으로 하지만, 각각 다른 메모리와 함께 패키징된다. 분기별 각 Huawei 칩의 로드맵 추정치와 물량은 SemiAnalysis Accelerator 모델에서 확인할 수 있다.
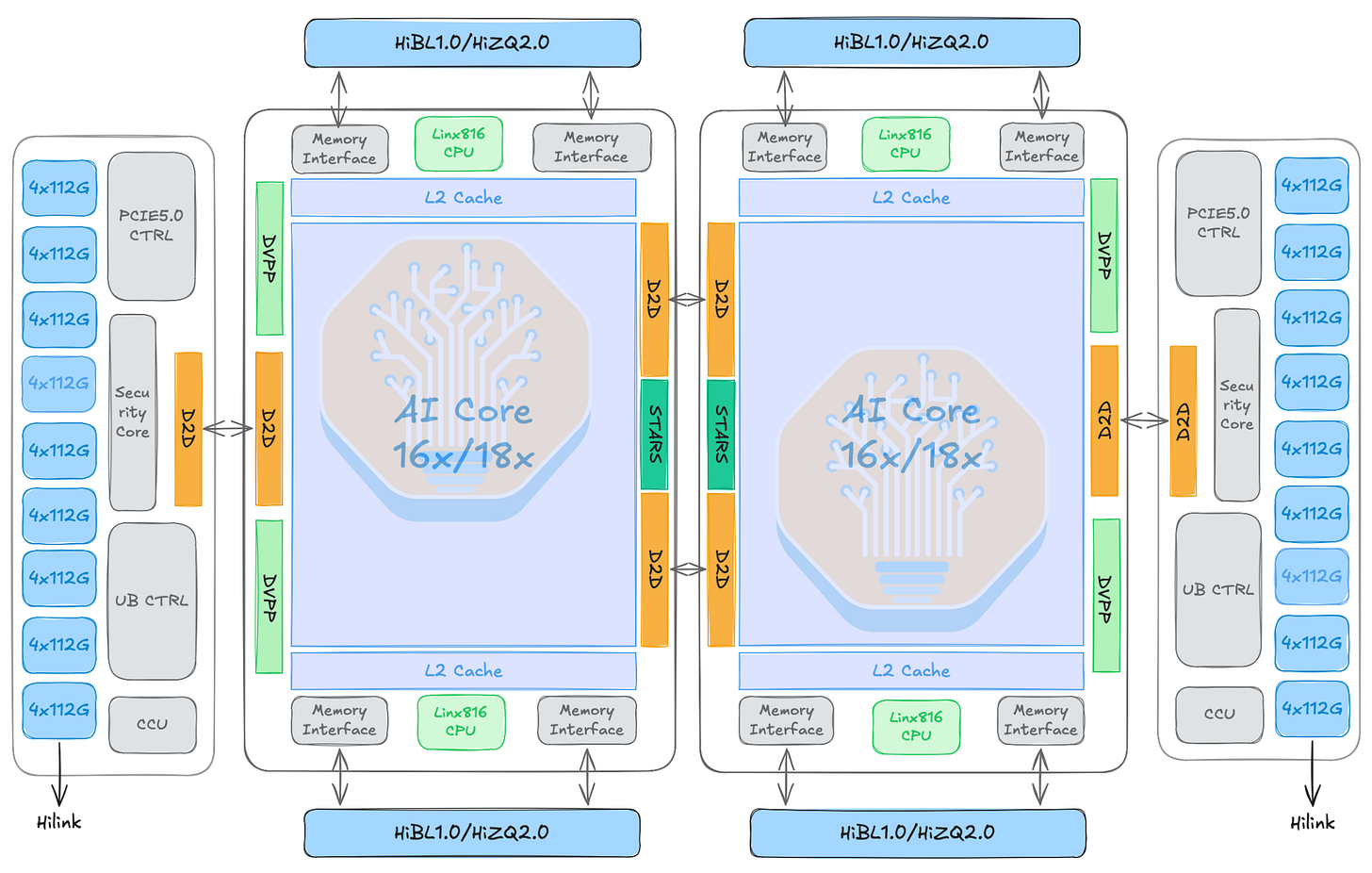
논의할 가치가 있는 칩 아키텍처의 두 주요 구성 요소는 AIC(AI Cube)와 AIV(AI Vector)다. AIC는 Ascend AI Core의 행렬/텐서 코어 쪽이다. GEMM, matmul, 컨볼루션류 텐서 연산, 어텐션 투영, FFN 선형 레이어 등 밀집 행렬 연산에 사용된다. Huawei 문서는 AIC를 분할(split) AI Core 아키텍처의 행렬 연산 코어로 기술한다. AIV는 벡터 코어 쪽이다. 활성화 함수, 정규화 부분, 마스킹, 리덕션, 타입 변환, 레이아웃 변환, matmul 주변의 후처리 등 요소별/벡터 작업을 처리한다.
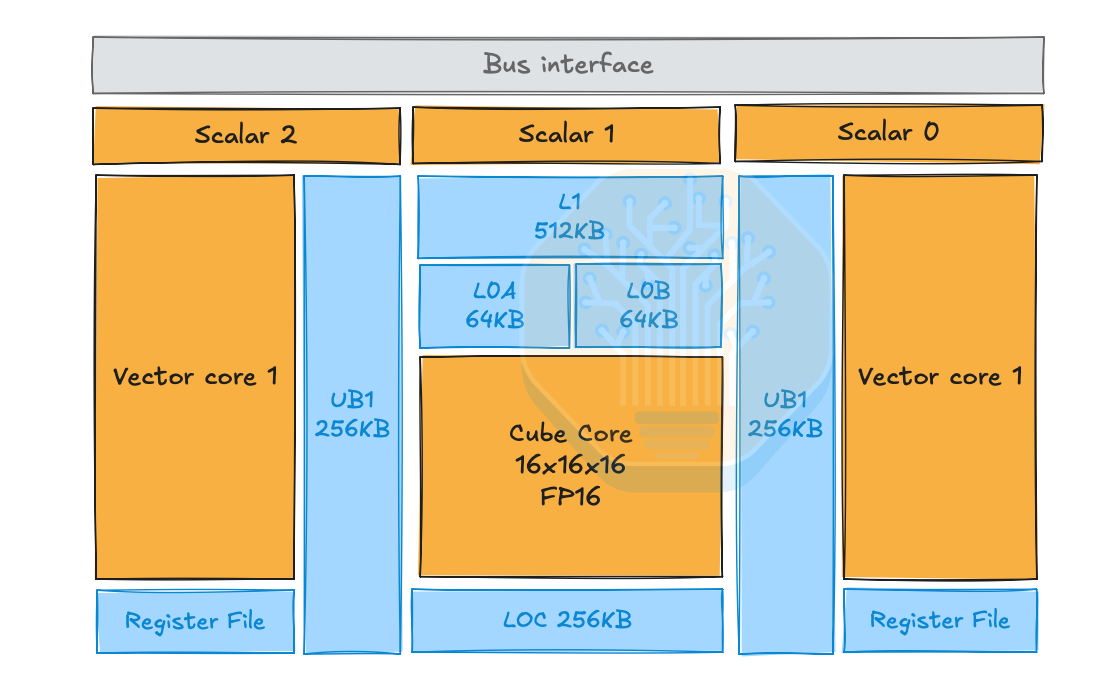
이는 TPU의 MXU와 유사하다. 다만 Ascend는 두 기능 간의 분할을 분리된 독립 코어로 더 직접적으로 노출하며, 각 코어가 자체 코드 세그먼트를 로드할 수 있고, AIV가 메시지를 통해 AIC를 구동하는 대신 AIC와 AIV가 독립적으로 코드를 실행하는 "듀얼 마스터 모드(dual-master mode)"도 갖추고 있다.
AI CPU는 디바이스 메모리에 직접 접근하는 디바이스 측 ARM64 실행 유닛이다. 분기가 많은 제어 흐름, 스칼라 로직, 동적 형상(dynamic-shape) 처리, 그리고 커널이 실행되기 전에 필요한 값 의존적 스케줄링/타일링 메타데이터처럼 SIMD/SIMT 코어에 잘 맞지 않는 작업에 대해 AI Core를 보완하는 데 사용된다. AI CPU가 디바이스에 상주하기 때문에 Ascend는 이러한 불규칙한 제어형 작업을 호스트 CPU로 왕복시키지 않고 로컬에서 유지할 수 있는데, 이 왕복은 지연(latency)과 파이프라인 버블의 주요 원인이다. AI CPU는 또한 전용 CCU가 해당 작업을 오프로드하기 전, 통신 오케스트레이션을 위해 역사적으로 구형 AICore → AICPU → SDMA 경로에 위치하던 유닛이기도 하다.
TPU 및 Trainium과 마찬가지로, Ascend 950은 전용 CCU 통신 엔진을 추가한다. 이 엔진은 연산 다이 옆에 위치하며, 원격 읽기 + 리듀스 + 로컬 쓰기, 그리고 로컬 읽기 + 원격 쓰기를 지원함으로써 AI Core 연산 용량을 소비하지 않고 집합 통신(collective-communication) 작업을 처리한다. 이점은 더 낮은 통신 지연, 더 적은 HBM 트래픽, 더 적은 사용자 버퍼 복사, 그리고 통신 오케스트레이션에서 연산 코어를 해방시켜 구형 AICore → AICPU → SDMA 경로를 피하는 데 있다.
Huawei DeepSeek v4 Pro 950DT 프로파일
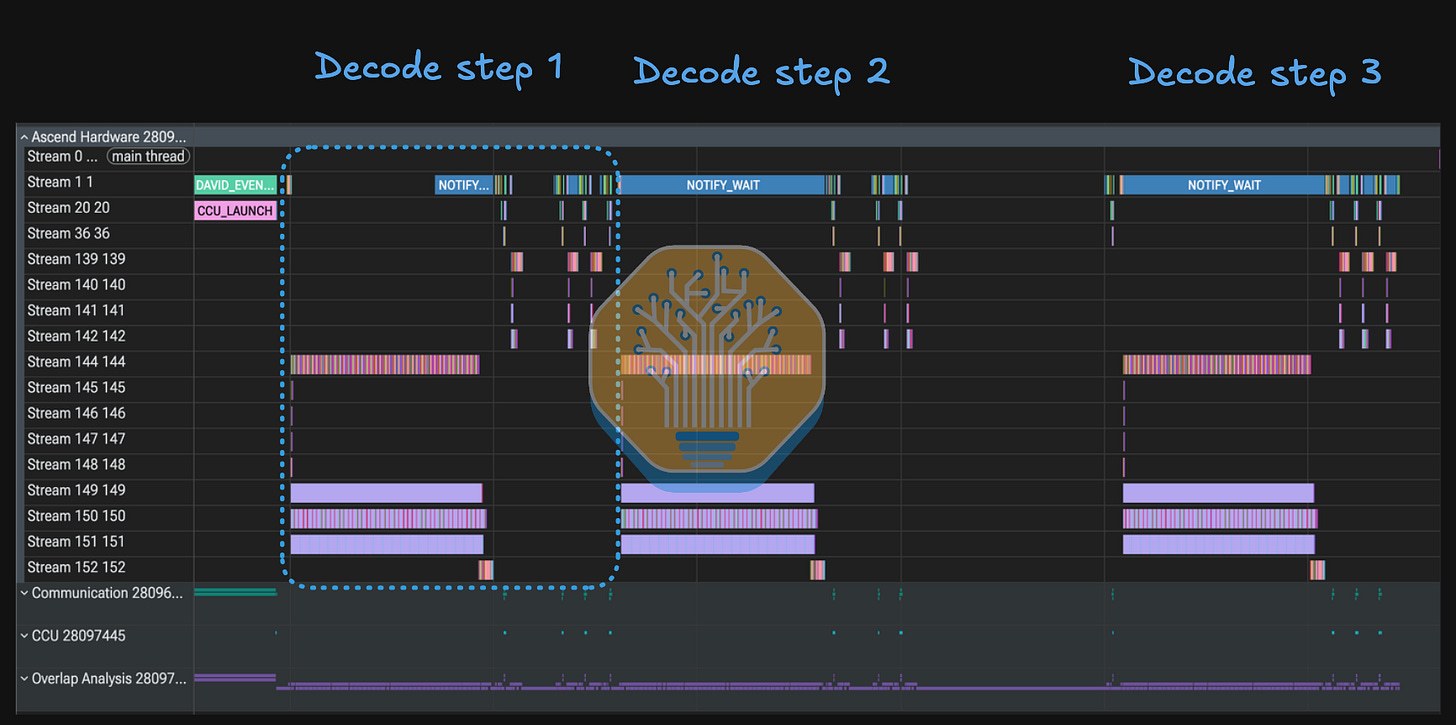
위는 16-rank DP/EP 배포 구성으로 실행되는 Ascend 950DT에서의 DeepSeek flash v4의 3단계 프로파일을 보여준다. 16-rank 집합 통신 참여와 활성 MoE 디스패치/컴바인 트래픽을 보여준다.
이제 대부분의 스택에서 표준이 되었듯이, CANN 역시 여러 스트림에서 실행될 수 있는 독립적인 연산 및 통신 연산자를 사용한다 — Cube와 Vector 코어 할당을 제어해 자원 경합을 피함으로써 성능이 개선된다. Prolog, Compressor, LightningIndexer 같은 연산은 중첩(overlap)될 수 있고, C4A Compressor는 완전히 숨길 수 있으며, 공유 전문가 연산은 라우팅 전문가 성능을 저하시키지 않고 라우팅 전문가 실행 아래에 숨길 수 있다.
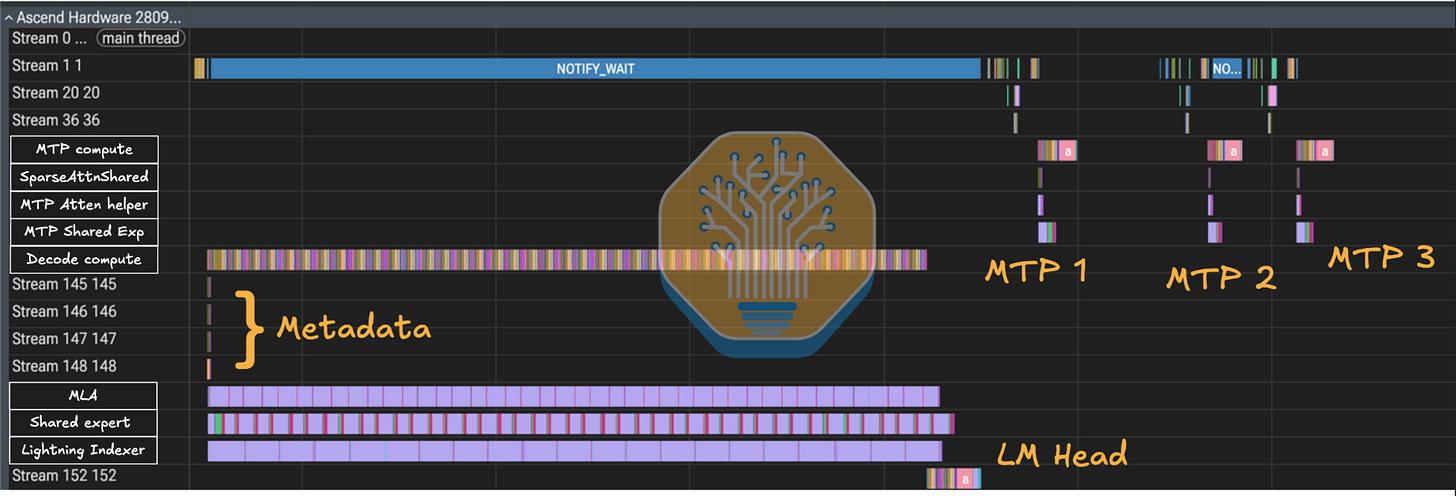
주어진 디코드 스텝을 확대하면, 서로 다른 구성 요소가 어떻게 스트림으로 분할되는지 볼 수 있다. 서로 다른 스트림의 연산은 디바이스에 여유롭고 적합한 자원이 있을 때 동시에 실행될 수 있다. 모델이 여러 스트림을 사용하는 이유는 한 레이어가 단일 직렬 체인이 아니라, 결과가 결합될 때만 동기화하면 되는 분기를 포함할 수 있기 때문이다 — 예를 들어 공유 전문가 연산이 라우팅 전문가 연산과 100% 중첩되는 경우.
위 다이어그램의 스트림 145–148은 메타데이터 스트림에 해당한다. 이 연산자들은 디코드 패스당 한 번 실행되며, 이후 커널이 재사용하는 값 의존적 스케줄러/타일링 메타데이터를 사전 계산한다. 이들은 디코드 스텝에서 유일한 AI CPU 연산이고, 전체 시간의 극히 일부를 차지하며, AI Core 연산과 완전히 중첩된다. 그 영향은 더 긴 컨텍스트 벤치마크에서 더 커질 가능성이 높은데, 미리 해결해야 할 시퀀스 길이 및 마스크 의존적 분할이 더 많기 때문이다.
DeepSeek v4에서 Huawei는 희소 어텐션과 LightningIndexer를 위한 값 의존적 스케줄러 단계를 호스트로 되돌리지 않고 AI CPU로 옮긴다. 이 메타데이터 연산은 런타임 시퀀스 길이, 마스크, 페이지드 KV 정보로부터 재사용 가능한 코어별 분할 텐서를 만든다. 그러면 SparseAttnSharedkv와 QuantLightningIndexer가 이를 소비해, 각 큐브 코어가 어떤 Batch/Head/Q-block/K-block 작업을 처리할지, 그리고 그에 대응하는 벡터 코어 리덕션 작업을 결정한다. 개념적으로 이는 페이지드 어텐션을 위한 FlashInfer의 호스트 측 계획(planning) 단계를 닮았다: 한 번 실행되어 레이어 전반에 걸쳐 상각되는, 저렴하고 동적 형상을 인지하는 설정 단계다. 유일한 차이는 Huawei가 그 동일한 계획 작업을 호스트가 아닌 온디바이스 AI CPU로 밀어 넣는다는 점이다.
위 다이어그램의 스트림 152는 LM 헤드, 마지막 레이어, 그리고 뒤에서 두 번째 레이어의 o_proj와 MoE를 포함한다. 이는 npugraph_ex 그래프 컴파일러의 결정으로, 아마도 npugraph_ex 런타임이 스트림 144에서 메인 그래프를 "완료"로 간주하는 동안 꼬리(tail) 작업이 비동기로 계속되도록 하기 위함일 것이다.
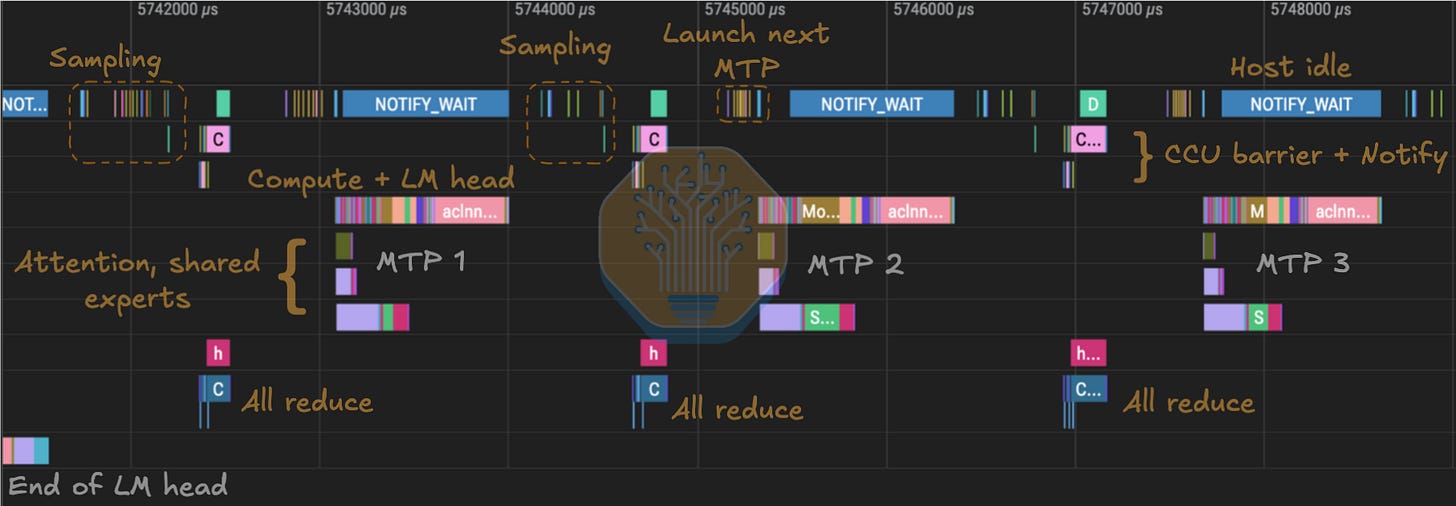
CANN은 또한 2024년에 MC²(merged compute-communication, 융합 연산-통신)를 도입했다. 이는 일반 커널도 HCCL 집합 통신도 아닌 부류의 융합 연산자로, 통신과 연산을 하나의 커널에 내장한다. DeepSeek v4 디코드에서 우리는 MoeDistributeDispatchV2와 MoeDistributeCombineV2 MC² EP 연산자가 사용되는 것을 볼 수 있다.
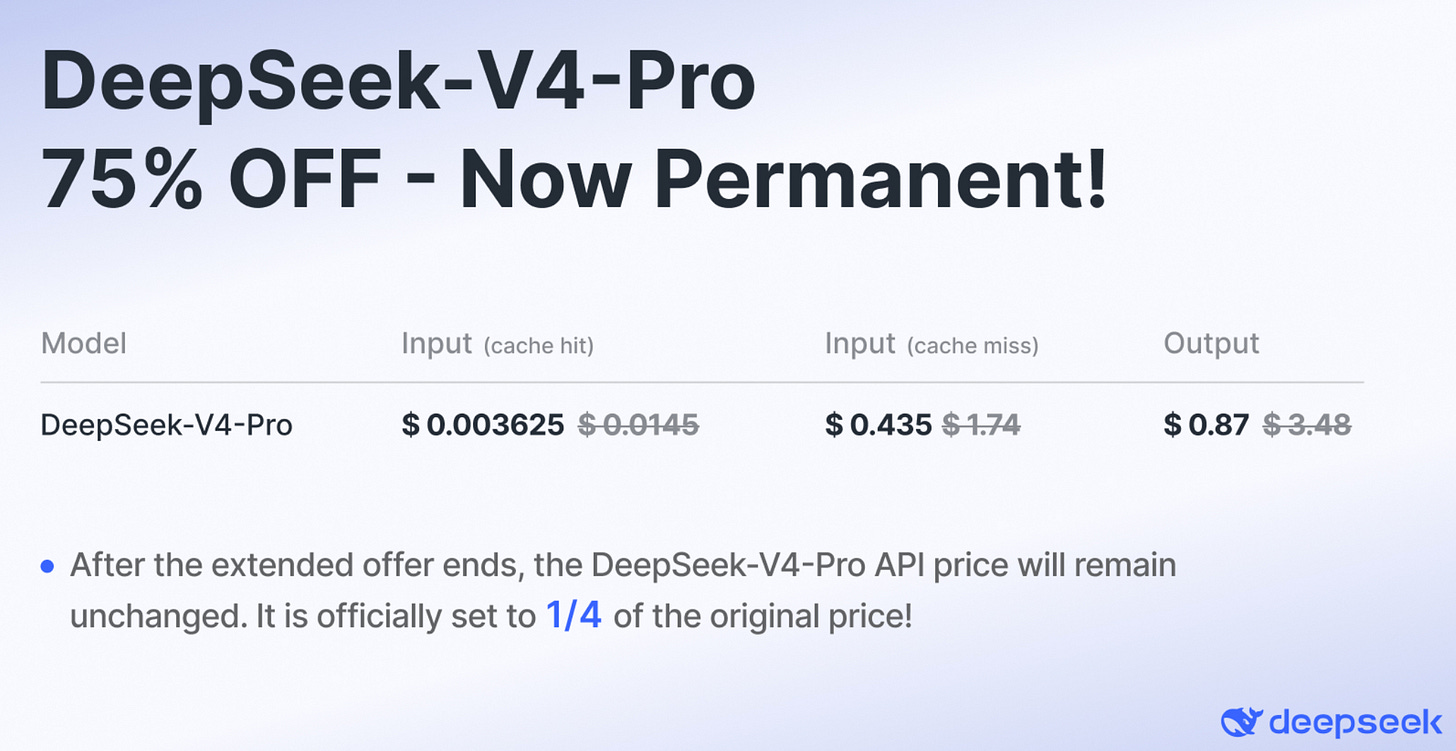
여기서 핵심 시사점은 Ascend가 Day 0에 DeepSeek v4에 대해 작동하고 최적화된 추론 인프라를 제공한다는 것이다. Huawei CANN 스택은 DeepSeek v4에 대한 Day 0 지원을 갖춘 단 두 스택 중 하나이며, 다른 하나는 NVIDIA의 CUDA다. 기사 앞부분에서 설명했듯, AMD 스택은 안타깝게도 Day 0에 잘 작동하지 않았다. 이는 DeepSeek v3/R1이 출시된 작년과 극명히 대조된다. 그때는 Day 0에 단 하나의 스택만 작동했다: NVIDIA CUDA 스택.
Ascend 950에 내부 코드명을 부여한 성경 이야기는 거인이 엎어진 채로 끝난다. 그러나 그 이야기 속 골리앗은 가만히 서서 다윗이 돌을 던지도록 내버려 두었던 반면, NVIDIA라는 골리앗은 끊임없이 움직이며 매년 새 아키텍처를 출시하고 기존 아키텍처를 개선한다. Huawei는 Day 0에 돌을 던질 수 있음을 입증했다. 움직이는 거인을 쓰러뜨릴 수 있을지는 아직 두고 볼 일이다.
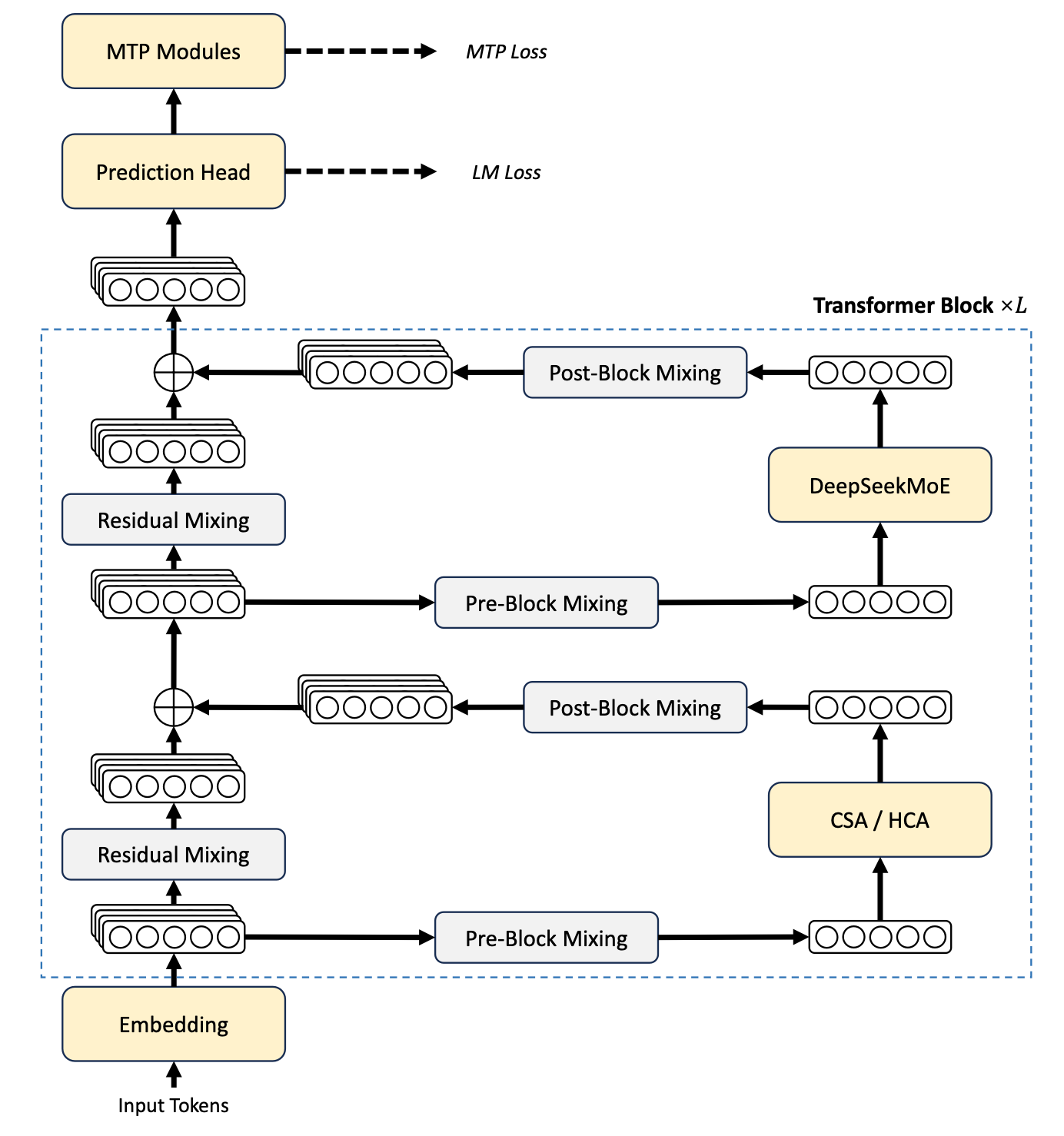
DeepSeek v4 아키텍처 심층 분석 및 공동 설계
(출처: DSv4 기술 보고서)
1M 컨텍스트 길이를 위한 추론 최적화
DeepSeek v4는 압축 희소 어텐션(CSA, Compressed Sparse Attention)과 고압축 어텐션(HCA, Heavily Compressed Attention)을 특징으로 하며, 다중 헤드 잠재 어텐션(MLA, Multi-head Latent Attention)에서 벗어난다. 이 설계는 KV 캐시 크기 감소에 의해 강하게 동기 부여되었다.
본질적으로 HCA의 KV 캐시는 KV 임베딩의 슬라이딩 윈도우와 압축된 KV 항목 집합으로 구성된다. 여기서 각 항목은 m′개의 토큰에 걸쳐 키/값을 하나로 압축한다(DeepSeek V4 Pro의 경우 m′ = 128).
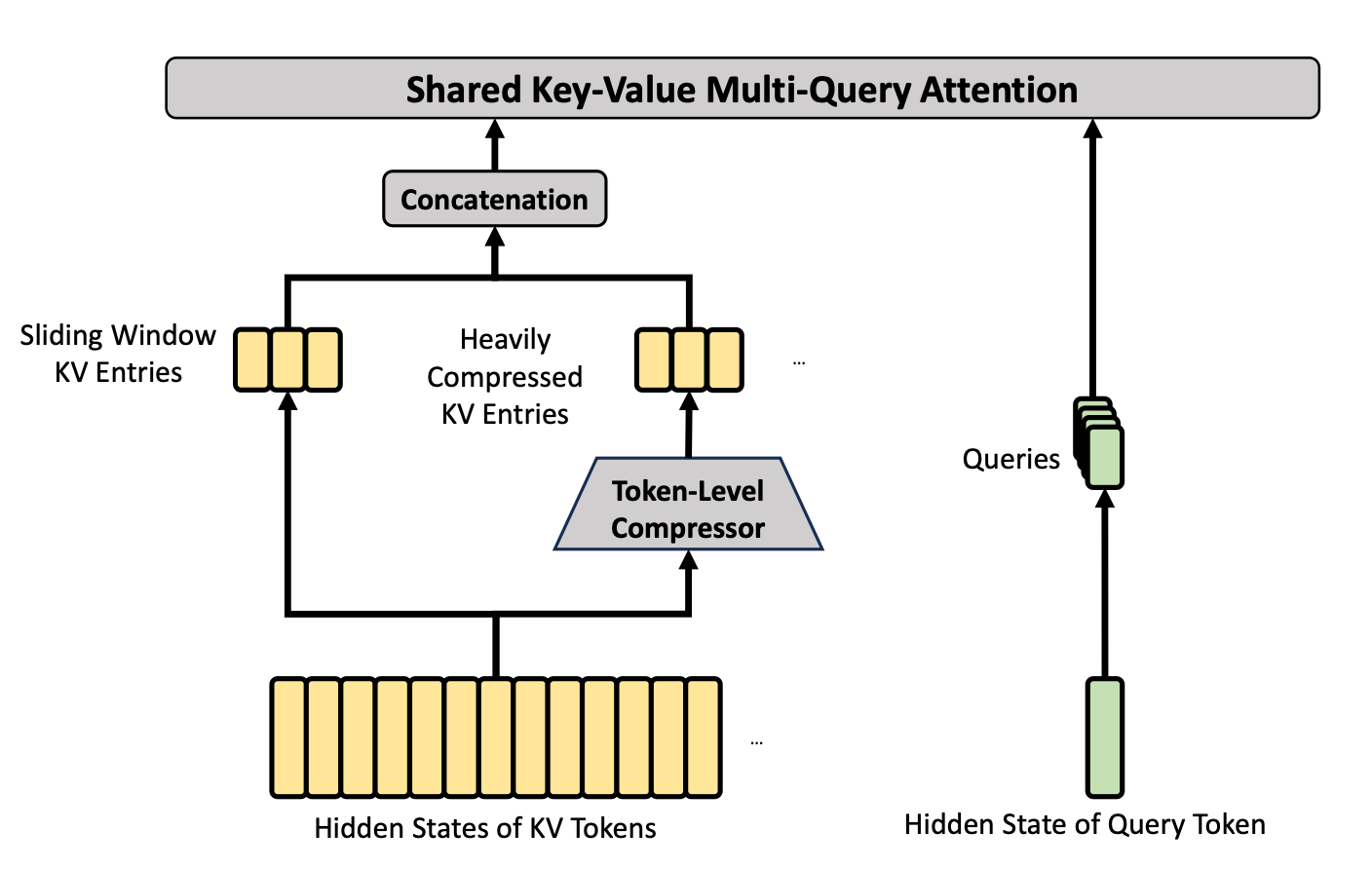
CSA는 HCA와 동일한 KV 캐시 압축 기법을 사용하지만 더 낮은 압축률(m=4)을 적용한다. CSA는 또한 라이트닝 인덱서(lightning indexer)를 사용해 주목할 토큰을 선택함으로써 압축된 KV 항목에 희소 어텐션을 적용한다. 이 희소 어텐션은 DeepSeek v3.2의 DeepSeek Sparse Attention을 계승한다.
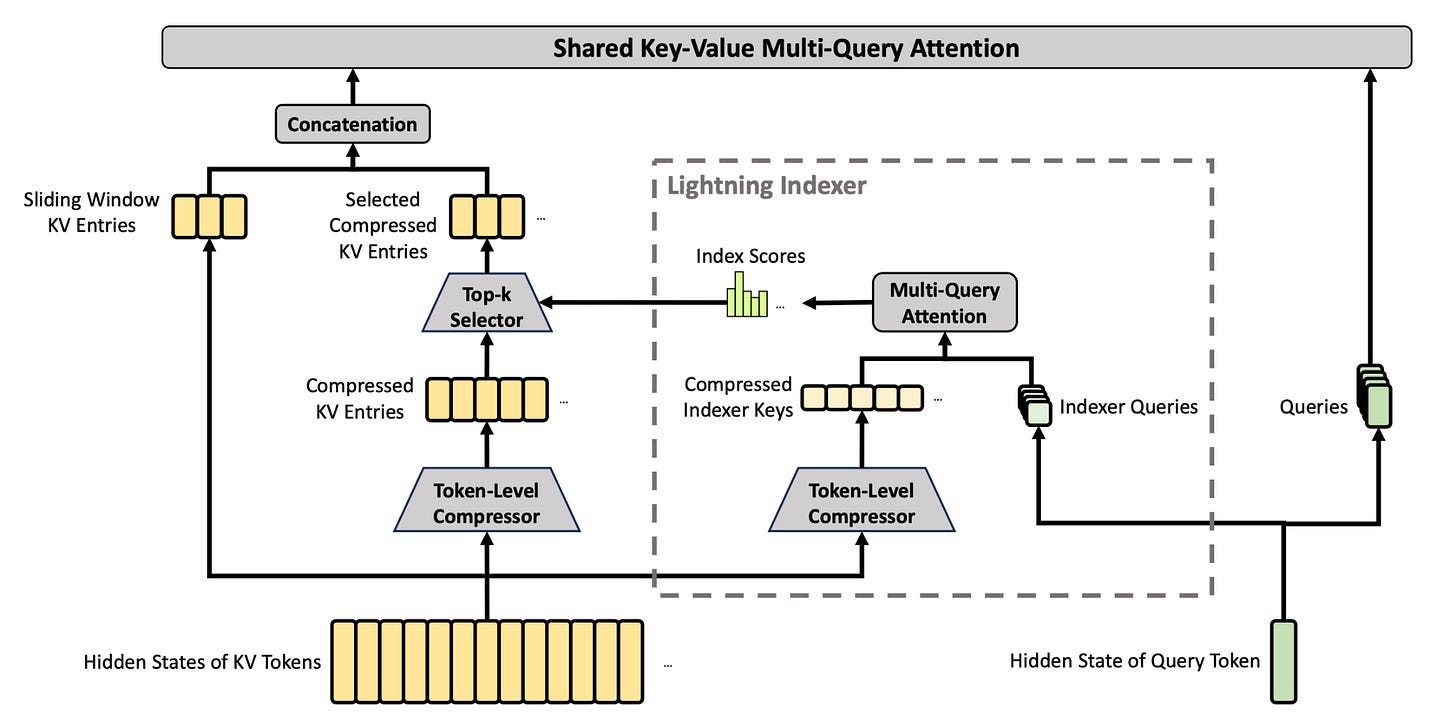
CSA와 HCA를 교차 배치(interleaving)함으로써, DeepSeek v4는 KV 캐시 크기를 공격적으로 압축하여 1M 컨텍스트 길이에서 50배의 KV 캐시 감소를 달성한다.
그러나 CSA와 HCA의 새로움은 서빙 프레임워크에 KV 캐시 관리상의 도전을 야기한다. 예를 들어 vLLM의 KV 캐시 메모리 할당자는 효율적인 메모리 로딩 패턴을 보장하고 프리픽스 캐싱 같은 서빙 기능을 지원하기 위해 복잡한 전략을 구현한다. 여기에는 CSA와 HCA 양쪽의 KV 압축률을 나누는 논리적 블록 크기를 설정하는 것과, 항목당 크기가 각기 다른 KV 캐시·compressor 상태·indexer KV를 저장하면서 발생하는 메모리 단편화를 피하기 위한 페이지 크기 버킷팅(bucketing) 전략이 포함된다.
결정론(Determinism)
RL 학습 안정성을 보장하기 위해 DeepSeek은 계산을 결정론적으로 만드는 데 전력을 다했다. 이 노력은 GPU 커널과 그들의 롤아웃 인프라를 들여다보면 드러난다. DeepSeek은 배치 크기와 무관하게 특정 리덕션 순서를 강제함으로써 배치 불변성(batch invariance)을 달성하기 위해 모든 연산에 대해 커스텀 커널을 작성했다. 여기에는 배치 불변 split KV 어텐션 순방향, GEMM, MoE 역방향 커널이 포함된다. 배치 불변 커널은 결정론적 리덕션 순서를 보장하지 않는 많은 인기 알고리즘 기법의 사용을 금지하기 때문에 성능 손실을 동반한다. DeepSeek은 자사 워크로드에 맞춰진 커널을 작성함으로써 — 예컨대 행렬 형상에 특화된 커널 — 이 성능 손실을 완화한다. 롤아웃 인프라 측면에서 DeepSeek은 모든 롤아웃을 재현 가능하게 만들기 위해 내결함성(fault tolerance)에 집중했다. DeepSeek은 각 생성 요청에 대해 토큰 단위 선행 기록 로그(write-ahead log)를 구축하여, 프리필이나 디코드 도중 선점된 요청이 재계산 없이 재개될 수 있도록 했다.
MegaMoE
DeepSeek V4 출시에는 MoE 레이어의 모든 연산을 더 잘 중첩시키는 새로운 융합 MoE 커널도 포함되었다. 전문가 병렬화를 적용한 MoE는 먼저 토큰 디스패치 all-to-all로 구성되고, 이어 Linear1, Activation, Linear2, 마지막으로 토큰 컴바인 all-to-all이 이어진다. Linear1과 Linear2는 그룹화된 GEMM 연산으로, 주어진 랭크의 각 전문가가 자신에게 라우팅된 토큰에 자신의 가중치를 적용한다. DeepSeek V4 논문의 저자들은 다른 구현들이 토큰 디스패치를 Linear1과, 컴바인을 Linear2와 중첩/교차시키지만, Linear1·Activation·Linear2 사이의 연산 경계에서 여전히 모든 전문가에 걸친 동기화가 존재한다고 언급한다. MegaMoE는 대신 전문가를 웨이브(wave)로 분할하고 각 웨이브를 별도로 스케줄링하여, 각 연산의 더 세밀한 중첩을 가능하게 하고 더 많은 통신 지연을 숨긴다. 이는 분산 GEMM 같은 연산-통신 융합을 연상시키는데, 여기서는 연산 커널과 의존적 통신 커널이 워크로드를 더 작은 조각으로 쪼개고 파이프라이닝하여 통신 지연을 숨김으로써 중첩된다.
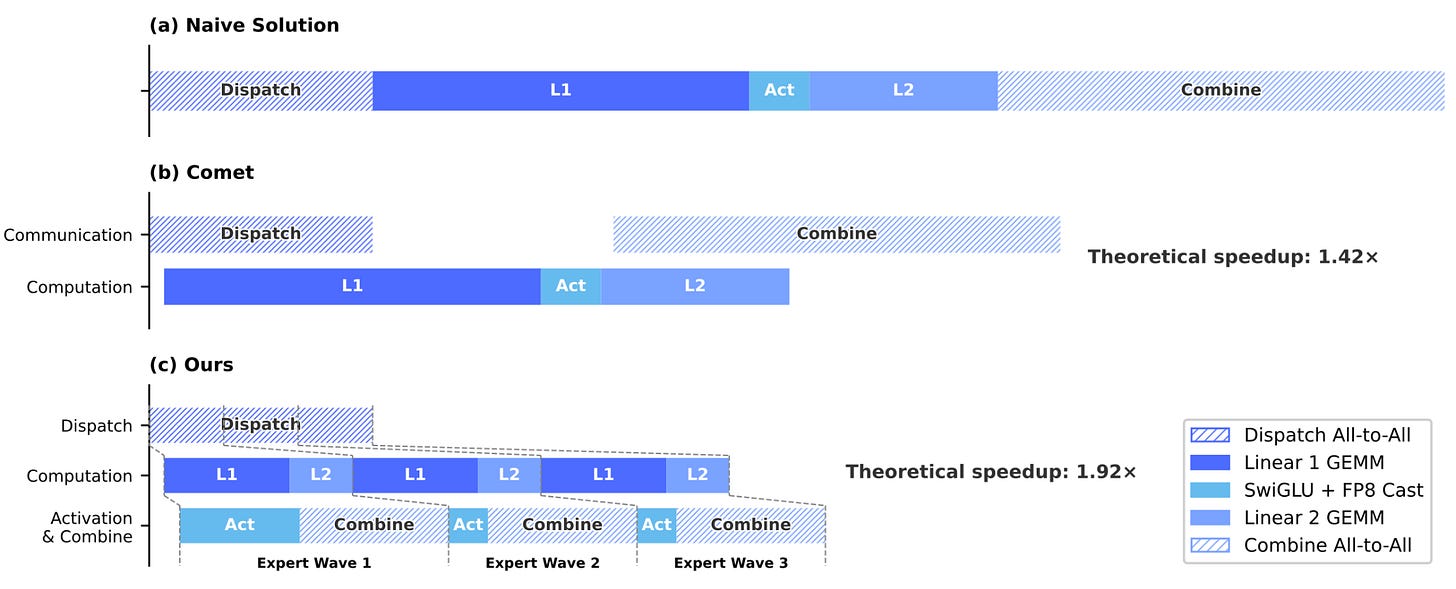
논문은 DeepSeek v4 Flash 구성에서 단순(naive) 커널 대비 이론적으로 1.92배의 속도 향상을 주장하는데, 이는 단순 커널이 시간의 거의 50%를 디스패치와 컴바인 통신에 소비함을 의미한다!
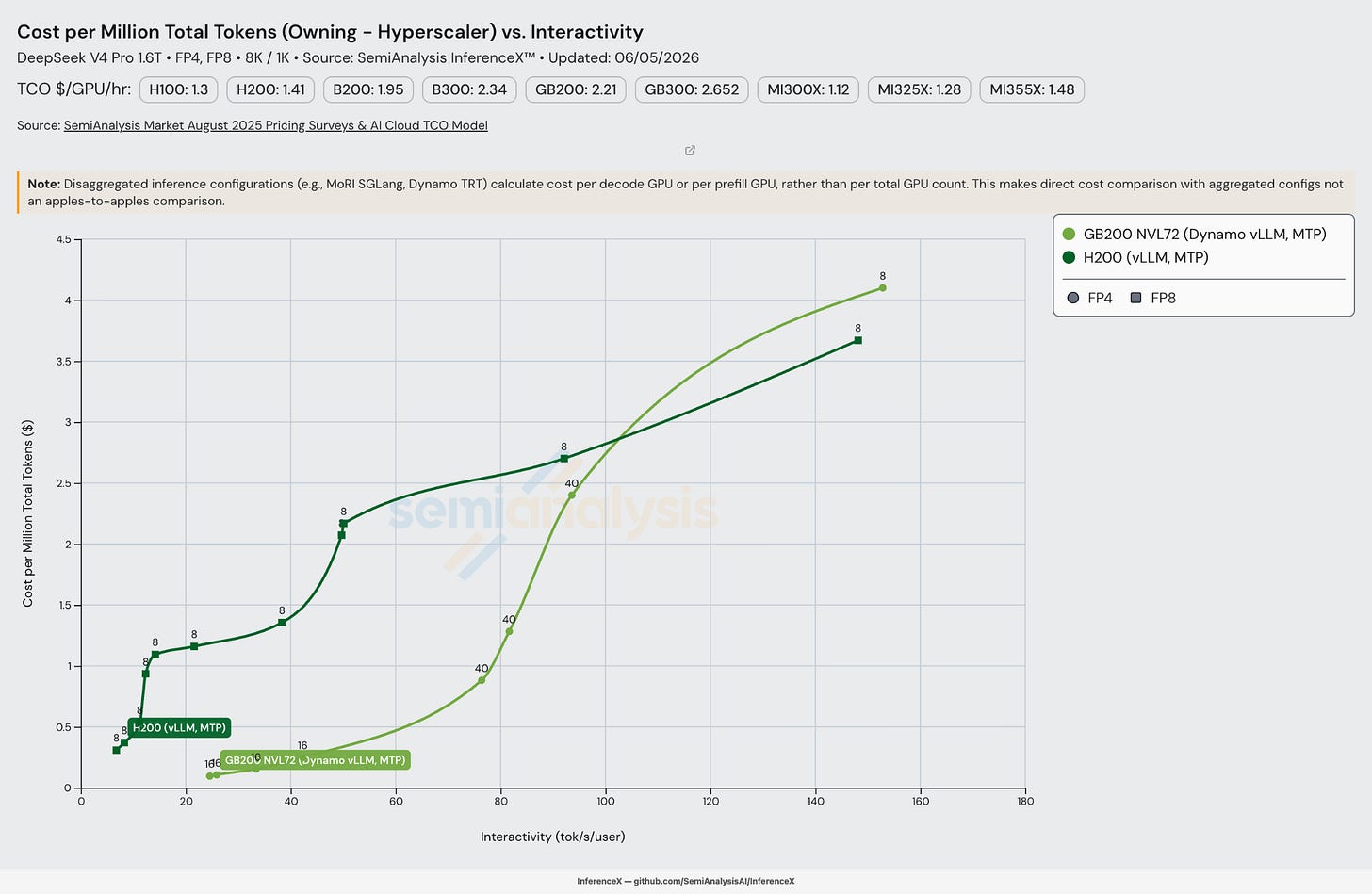
이제 성능 벤치마크를 자세히 논의했으니, H200과 GB200 NVL72에서 DeepSeek v4를 실행할 때의 총소유비용과 토큰당 비용을 논의해 보자.
DeepSeek v4 Pro의 일반적인 서빙 범위인 약 40–60 tok/s/user 상호작용성을 살펴보면, 백만 토큰당 비용 면에서 GB200 NVL72가 10배 이상 저렴함을 알 수 있다. 이는 GB200 NVL72가 72개의 GPU를 B200의 InfiniBand보다 18배 빠른 속도로 연결하는 NVL 백플레인을 활용할 수 있어, 광역 전문가 병렬화 같은 최적화의 사용이 가능하기 때문이다.
원문: newsletter.semianalysis.com